3.1 The Appraisal View
Covid models have been widely criticized for their poor predictive performance (
Avery et al. 2020a;
Ioannidis, Cripps, and Tanner 2020;
Winsberg, Brennan, and Surprenant 2020). Against the background of such criticisms, we argued that when assessing Covid models, we should not only look at their forecast accuracy but also at their performative contributions (
van Basshuysen et al. 2021). More specifically, while there are good reasons to think that many Covid models have been predictively far from impressive, it is unclear whether this alone is enough to conclude that they were bad models, full stop. For one, we emphasize that in assessing the epistemic contributions of Covid models, we must understand a majority of their outputs as conditional forecasts
6 for counterfactual scenarios rather than as straightforward predictions of actual courses of events (see also
Fuller 2021;
Schroeder 2021). So, if a conditional forecast predicts millions of deaths for a scenario where no measures are taken and, in response to that, aggressive suppression measures are implemented, it should be no surprise that actual death tolls are much lower than the forecast. Due to the policy measures implemented, the relevant quantity to assess forecast accuracy is now a counterfactual quantity that cannot be observed and at best estimated (
Friedman et al. 2021;
Winsberg and Harvard 2022). To be sure, many Covid models have also been used to issue a range of different scenario forecasts, including some capturing scenarios that more closely resembled actual policy trajectories taken. But even when looking at these scenario forecasts, some critics maintain that forecast accuracy has been poor, with many models overestimating infection numbers and deaths (
Winsberg, Brennan, and Surprenant 2020;
Winsberg and Harvard 2022).
So, should we conclude that Covid models have been bad models? In
van Basshuysen et al. (2021) we argued that such a conclusion would be too hasty, sketching what I call the
appraisal view. Specifically, we maintain that we should not only focus on forecast accuracy when evaluating Covid models, but should instead take an all-things-considered view, which takes into account their performative contributions to the achievement of (some) social goals (though possibly at the expense of others; see
Winsberg and Harvard 2022). In a nutshell, the appraisal view maintains that it can be a good-making feature of Covid models that they helped individuals understand the likely trajectories of the pandemic, choosing response profiles that were (more) consistent with their preferences, and thereby contributing to lower infection numbers and death tolls. Performative effects such as these are part of what we should consider when assessing the overall goodness of models.
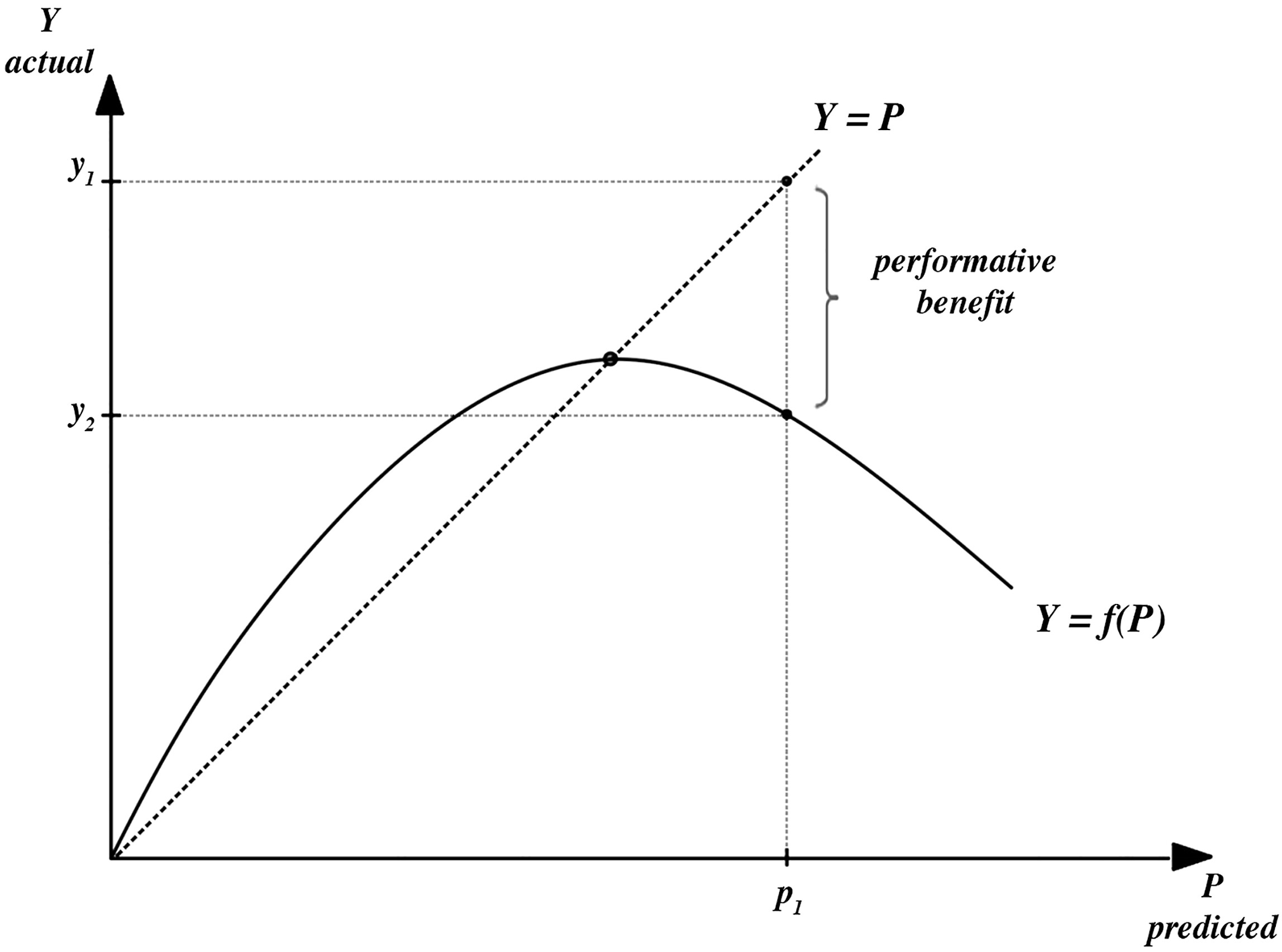
Figure 1 captures this line of thinking in an idealized fashion.
Focusing on infection numbers as the quantity to be predicted, the P-axis plots model predictions and the
Y-axis plots actual infection numbers. In a non-performative world with perfectly accurate models, the predictions from a model would be on the dotted 45° line, perfectly coinciding with observed values, i.e.,
. In a world with model performativity, the solid curve captures how infection numbers depend on agents’ behavioral response to model predictions according to some response function
. In a nutshell, for low predicted infection numbers, individuals choose more risky behaviors, e.g., by bending lockdown rules or isolation requirements, or simply increasing contacts. In the upper right area, the response curve slope turns negative.
7 Here, high predicted numbers (
) of infections lead to individuals reducing contacts, thereby realizing lower numbers than initially predicted (
). On the appraisal view, the difference between
and
can be understood as a benefit afforded by the model’s performativity. Even though its predictions have not been accurate (
), the actual outcome is, I assume here for simplicity, preferable over the alternative.
8 And since this outcome is caused, in part, by the model, achieving this outcome is a good-making feature
of the model.
Is the appraisal view plausible? Endorsing performativity as a good-making feature may seem inappropriate for a wide range of scientific models. When a model is designed for purely epistemic purposes, it will often seem unhelpful at best and problematic at worst to think that a causal coupling between a model and target that systematically prevents a model from producing accurate forecasts can be a good-making feature. However, Covid models were constructed and used specifically for the purpose of (helping decision-makers with) inhibiting and controlling the spread of the virus, and the performative effects outlined in
van Basshuysen et al. (2021) promote those same practical goals. So, broadly following an adequacy-for-purpose type view on model appraisal (
Parker 2020), why should we
not consider the achievement of these goals to be a good-making feature if models causally contributed to it?
Winsberg and Harvard (2022) argue that performative effects should never be considered good-making features of models. One of two main worries they flag is that any inaccurate forecast could always be explained as the result of performative effects and allowing performative effects to count toward a positive appraisal of a models’ overall goodness would only make it easier to conjure up such ad hoc defenses. An important constraint on the appraisal view, therefore, should be that models’
counterfactual forecasts (sans performativity) must be approximately accurate:
9 if a model forecasts high infection numbers (
),
10 but much lower numbers are eventually observed (
), it must be true that the difference between
and
is prevalently due to performative effects and not simply due to the model getting
wrong while also failing to anticipate how individuals’ response to
would move us to
. Even under this narrower constraint, however, Winsberg and Harvard emphasize that we should never celebrate inaccurate, pessimistic projections as good-making features of models—even if they contributed to moving behavioral response in prima facie beneficial ways (
2022, 5). Specifically, they argue that the main purpose of Covid models was to aid decision-makers
11 with understanding the cost-benefit profile of potential courses of actions. So, if Covid models systematically overestimated numbers (i.e., they did not just fail to predict
, but got
wrong as well), then those models would distort the cost-benefit profile of available actions by unduly exaggerating some of the costs and benefits involved (e.g., how many lives could be saved). Of course, due to lack of reliable epistemic access to the relevant counterfactuals, telling whether models get their counterfactuals approximately right is extremely difficult in practice. But as the worries flagged by Winsberg and Harvard make clear, model appraisal must at least involve sincere attempts to assess whether this is so. So, when modelers explain away prima facie predictive failures and defend the goodness of their model by unsubstantiated blanket appeals to performativity, these defenses need to be scrutinized, and we may reasonably require modelers to offer compelling grounds to think that their models (1)
did get their counterfactuals approximately right and (2) performativity is
really what explains the differences between forecasts and actual, observed outcomes.
Even if such efforts were successful, however, there is a second important problem with the appraisal view that we anticipated in
van Basshuysen et al. (2021) and that Winsberg and Harvard further discuss. To appreciate this problem, let me cast the appraisal view in somewhat clearer outlines:
Appraisal: The overall goodness of a model (e.g., in terms of a wide understanding of
adequacy-for-purpose; see
Parker 2020;
van Basshuysen 2022), is a function of (1) whether a model properly performs its
epistemic functions, e.g., issuing accurate predictions, providing adequate explanations or facilitating understanding of a phenomenon, and (2) whether a model contributes to the achievement of the
practical purposes for which the model was constructed, including by causally affecting desired kinds of change in a target system (see
Tee 2019).
As we emphasize in
van Basshuysen et al. (2021, 123), the second condition can be met in two significantly different ways, giving rise to two quite different renditions of the appraisal view. To see this, let us assume that there is a set of moral and political values
, shared by stakeholders in a population. Assume model
is built to promote a set of practical purposes
(e.g., managing a pandemic) that cohere with
in a target
. One rendition of the appraisal view is
evaluative. On this rendition, a model
is, other things being equal, a better model if it made larger differences to the achievement of
. As the tense suggests, this rendition is
backward-looking: given a model that has been used in such-and-such ways, we consider what differences it made to the achievement of
and this guides our assessment of its overall goodness. Another, quite different rendition of the appraisal view is
normative. According to this rendition, a model can (and perhaps should) be
made better, other things being equal, by being
made more performative, i.e., able to make/actually making larger differences to the achievement of
.
In
van Basshuysen et al. (2021, 123), we caution that this normative rendition of the appraisal view is highly problematic, since it invites tuning model forecasts to steer people’s behaviors in certain directions. Even if the purposes that modelers sought to promote this way were successfully tracking an uncontroversial set of values
, we should think that this practice is nevertheless highly questionable. Models are widely considered to be epistemic instruments: to the extent that they help with the achievement of practical purposes, this should be only as a function of sincere epistemic contributions that they make, but not by meddling with these contributions to effect specific outcomes. We call violations of this constraint
wishful modeling (ibid.). In a nutshell, wishful modeling happens when non-epistemic values, e.g., concerning the desirability of certain social outcomes, steer the construction and use of models with the explicit aim of manipulating a target system in a specific way. While it is now widely recognized that non-epistemic values can, should, or necessarily do, often play (legitimate) roles at various stages of scientific inquiry (
Biddle 2013;
Elliott 2017;
Elliott and McKaughan 2014;
Douglas 2009;
Winsberg 2012), using models to specifically steer people’s behaviors would contravene even liberal views on acceptable value influences. The concern that the appraisal view may open the door toward misuses of scientific models becomes even more acute when considering potential damage to public trust in model-based science. Narratives that cast models as engines of persuasion and manipulation for intransparent goals could significantly contribute to the ongoing erosion of public trust in science (cf.
Kreps and Kriner 2020). What this suggests, and what we emphasized in
van Basshuysen et al. (2021), is that we must shut the door firmly on the normative rendition of the appraisal view. Winsberg and Harvard, however, worry that doing so will be difficult in practice and use an analogy to draw out the problem:
Imagine holding an annual race in which we tell runners that the goal is to complete 10 km in the fastest possible time, but where, year after year, we award the medals to runners who most quickly reach the 5 km mark. Hopefully it is clear that we cannot neatly separate how runners will be evaluated from what they will eventually adopt as their goal. The same will be true of modelling. If those who judge the suitability, adequacy, or usefulness of a model give it high marks when it succeeds performatively (according to the values of the judges in question), they will be sending the signal that modellers should adopt this goal. (
Winsberg and Harvard 2022, 4)
So, even if we managed to ensure that models got their counterfactuals right, and pressed modelers to demonstrate that this is so, counting (some) performative effects as good-making features of models could induce incentives that divert modelers’ attention away from epistemic goals such as forecast accuracy toward performative goals, such as issuing forecasts that are likely to steer behaviors in putatively beneficial ways. Modelers’ goals, we might insist, should primarily focus on doing as good of an epistemic job as possible, which includes getting counterfactual and actual scenario forecasts right, and the best way to ensure this is to exclude performative effects from consideration in model appraisal. According to Winsberg and Harvard, then, the best way of shutting the door on the normative rendition of the appraisal view is to reject the appraisal view altogether.
So if appraisal is no good, how should we deal with model performativity instead? Let me consider a second strategy for dealing with performativity, the mitigation view, which, at face value, promises to evade these concerns, but ultimately falls prey to similar worries.
3.2 The Mitigation View
The mitigation view aims to deal with model performativity by getting rid of it. Starting in the 1950s, economists and political scientists began investigating how publicizing election polling results could alter election outcomes (
Grunberg and Modigliani 1954;
Simon 1954). Two widely-discussed ways in which this could happen are the
bandwagon and
underdog effects.
12 The former captures a case where a candidate A is predicted to win an election against B and, because of this public prediction, more voters than otherwise turn out in support of A. The underdog effect describes the converse: if A is predicted to be ahead in the race, some voters who would have otherwise voted for A end up voting for B, because they want to vote for whoever is behind in the race. In either case, the first-stage prediction of the election result will turn out to be inaccurate because agents respond to the public prediction—it is performative.
Against the background of such cases, Grunberg and Modigliani as well as Simon undertook analytical investigations to determine conditions under which public predictions could be modified so as to
endogenize peoples’ behavioral response, i.e., to explicitly model how individuals respond to a prediction and to formulate an adjusted prediction that takes that response into account and brings predictions in line with actual results in equilibrium. Similar efforts to endogenize peoples’ behavioral response have recently been undertaken by epidemiological modelers and computer scientists (see
Avery et al. 2020b for an overview; see
Perdomo et al. 2021 for efforts in machine learning).
Figure 2 captures how following the mitigation strategy could look like in the Covid modeling case.
The response curve is the same as before. In addition, the dash-dotted lines and arrows capture schematically how behavioral response is endogenized.
13 The first-stage prediction,
, is plugged into a function
that captures the performative response curve. This yields
, which then figures as the second-stage prediction
. When publicly predicting
, by taking into account how people would have responded to
, we move to a different segment of the response curve, which gives us
. In an iterative process of taking the stage-n outcome
to yield the stage-n+1 prediction
, we eventually reach an equilibrium point
that intersects the 45° line where predictions perfectly coincide with actual outcomes.
Is this a good way of dealing with performativity because it avoids moral and political value judgments encroaching on the appraisal and thereby the construction of scientific models? Not necessarily. Importantly, when taking the mitigation route, is now higher than , which would have been the outcome under the appraisal route. So, if we continue to assume for simplicity that minimizing infection numbers is good, endogenizing people’s behavioral response is a worse strategy in terms of our practical purposes, but is epistemically superior, since predictions now coincide with actual outcomes.
What is important to note, then, is that there can be
trade-offs between epistemic and practical purposes and the mitigation view settles this trade-off in favor of epistemic purposes at the potential cost of inferior social outcomes. The appraisal view, by contrast, is open to accepting compromises in predictive performance in exchange for practical benefits. Crucially, this means that
both routes reflect a value-laden stance on the trade-off, and despite initial appearances to the contrary, the mitigation strategy is subject to concerns about illegitimate value influences, too (see also
Brown 2017). Why, after all, should we think that it is overall better to have a model accurately predict infection numbers when this means that those numbers would be higher than if we had not endogenized behavioral response? Why should not we think it can be preferable to have a model overestimating infection numbers (i.e., making first-stage predictions that do not consider performative effects), thereby contributing to behaviors that realize lower numbers? Answering these questions, necessarily, involves moral values because the choice of whether to endogenize or not is not only a choice between better and worse predictive performance but also a choice between two different social outcomes (
and
). Even if, say, lowering infection numbers were an uncontroversial moral good, and modelers decided to refrain from endogenizing to help achieve this good, it is not obvious that they should: modelers are not suitably legitimized to make choices between social outcomes on our behalf, even if their values magically coincided with a hypothetical aggregate public value profile.
The mitigation view hence leaves us an uncomfortable epistemic-ethical bind. Model performativity can sometimes yield beneficial outcomes, and there are reasons to think that these may be counted toward the overall goodness of a model in epistemic-practical terms. Such a view, however, must also manage concerns about illegitimate value influences that threaten to undermine the epistemic integrity of specific models, and model-based science more generally. An alternative can be to “endogenize away” performative effects by modeling how agents respond to predictions. However, this route similarly faces difficult questions about what legitimizes modelers to make modeling choices that ultimately select different social outcomes than would have been realized without mitigation attempts. Recognizing this helps us appreciate that Winsberg and Harvard’s call to reject the appraisal view for the threats posed by its normative rendition does not take us very far when the relevant alternative, mitigation, is subject to similar concerns about illegitimate value influences. Worries that the appraisal view opens the door to such influences are hence misplaced—the door has been open all along, but proponents of mitigation-type approaches have so far not adequately recognized it. Faced with a choice between a rock and a hard place, let me now turn to explore whether we can find some smoother pebbles in between, by considering (1) what principles could help keep the most severe value-related concerns affecting both views at bay and (2) how contextual factors bear on the adequacy of both strategies for managing performativity.