

Dynamic movement primitives in robotics: A tutorial survey
Abstract
1. Introduction
How do biological systems, like humans and animals, execute complex movements in a versatile and creative manner?
How artificial systems, like (humanoid) robots, can execute complex movements in a versatile and creative manner?
1.1. Existing surveys and tutorials
| Paper/survey/tutorial | Topics | Description |
|---|---|---|
| Schaal et al. (2007) | • Classical DMPs | A tutorial that provides a unifying view of the two main approaches used to develop computational motor control theories, namely, differential equations and optimal control. In this work, discrete and rhythmic DMPs (Ijspeert et al., 2002c; Schaal, 2006) are presented as a computational model of the motor primitives’ theory (Mussa-Ivaldi 1999) that unifies nonlinear differential equations and optimal control. The tutorial has a section dedicated to DMP parameter optimization beyond ILs. Schaal et al. show how to optimize DMP parameters to minimize various costs describing, for instance, the total jerk of the trajectory or the end-point variance. |
| • Online adaptation | ||
| • Optimization | ||
| Ijspeert et al. (2013) | • Classical DMPs | A paper on classical DMPs that in addition to its scientific contribution, it presents both discrete and rhythmic formulations, mostly developed in (Ijspeert et al., 2002c, 2002; Schaal, 2006), and their application in IL and movement recognition. The paper also presents extensions of the classical DMP formulation to prevent high accelerations at the beginning of the motion, to avoid collisions with unforeseen obstacles (Pastor et al. 2009), and to generalize both in space (e.g., reach a different goal) and time (e.g., produce longer/shorter trajectories). |
| • Online adaptation | ||
| • Coupling terms | ||
| • Generalization | ||
| Pastor et al. (2013) | • Classical DMPs | A paper on classical DMPs that in addition to its scientific contribution, it presents both discrete and rhythmic formulations, mostly developed in (Ijspeert et al., 2002c, 2002; Schaal, 2006). The paper also presents extensions of the classical DMP formulation to avoid collisions with unforeseen obstacles (Pastor et al. 2009) and to learn impedance control policies via Reinforcement Learning (RL) (Buchli et al. 2011b). The key difference between Ijspeert et al. (2013) and Pastor et al. (2013) is the section dedicated to the sensory association and online, context-aware adaptation of DMP trajectories using the associative skill memory framework developed in Pastor et al. (2011) and Pastor et al. (2011a). |
| • Online adaptation | ||
| • Coupling terms | ||
| • Impedance learning | ||
| Deniša et al. (2016b) | • Classical DMPs | A tutorial on CMPs, a framework developed to generate compliant robot behaviors that accurately track a reference trajectory. CMPs exploit classical DMPs to generate the desired kinematic landscape and encode task-dependent dynamics as a combination of Gaussian basis functions (torque primitives). The tutorial shows how to learn torque primitives from training data, how to generalize CMPs to new situations, and how to combine existing CMPs to synthesize new robot motions. |
| • Compliant Movement Primitives (CMPs) |
| Survey and tutorial | Topics | Description |
|---|---|---|
| This paper | DMP tutorial | This tutorial survey conducts a wide scan of the existing DMP literature with the aim of categorizing and presenting the published work in the field. The main objective of this comprehensive literature review is to give the reader an exhausting overview on DMP-related research, on its major achievements, as well as on open issues and possible research directions. Our tutorial survey also provides a structured and unified formulation for different methods developed starting from the classical DMPs proposed by (Ijspeert et al., 2002c; Schaal, 2006). We believe that such formulation contributes to an easier understanding of different methods and extension that can be found in the literature, clarifying connections and differences among the existing approaches. The tutorial survey also provides an analysis on pros and cons of various methods and a discussion with guidelines for different application scenarios. |
| • Classical | ||
| • Orientation | ||
| • SPD | ||
| • Joining | ||
| • Generalization | ||
| • Online adaptation | ||
| DMP survey | ||
| • (Co-)Manipulation | ||
| • Variable impedance | ||
| • Physical interaction | ||
| • Rehabilitation | ||
| • Teleoperation | ||
| • Motion recognition | ||
| • Reinforcement, deep, and lifelong learning |
1.2. Systematic review process
1.3. A taxonomy of DMP-related research
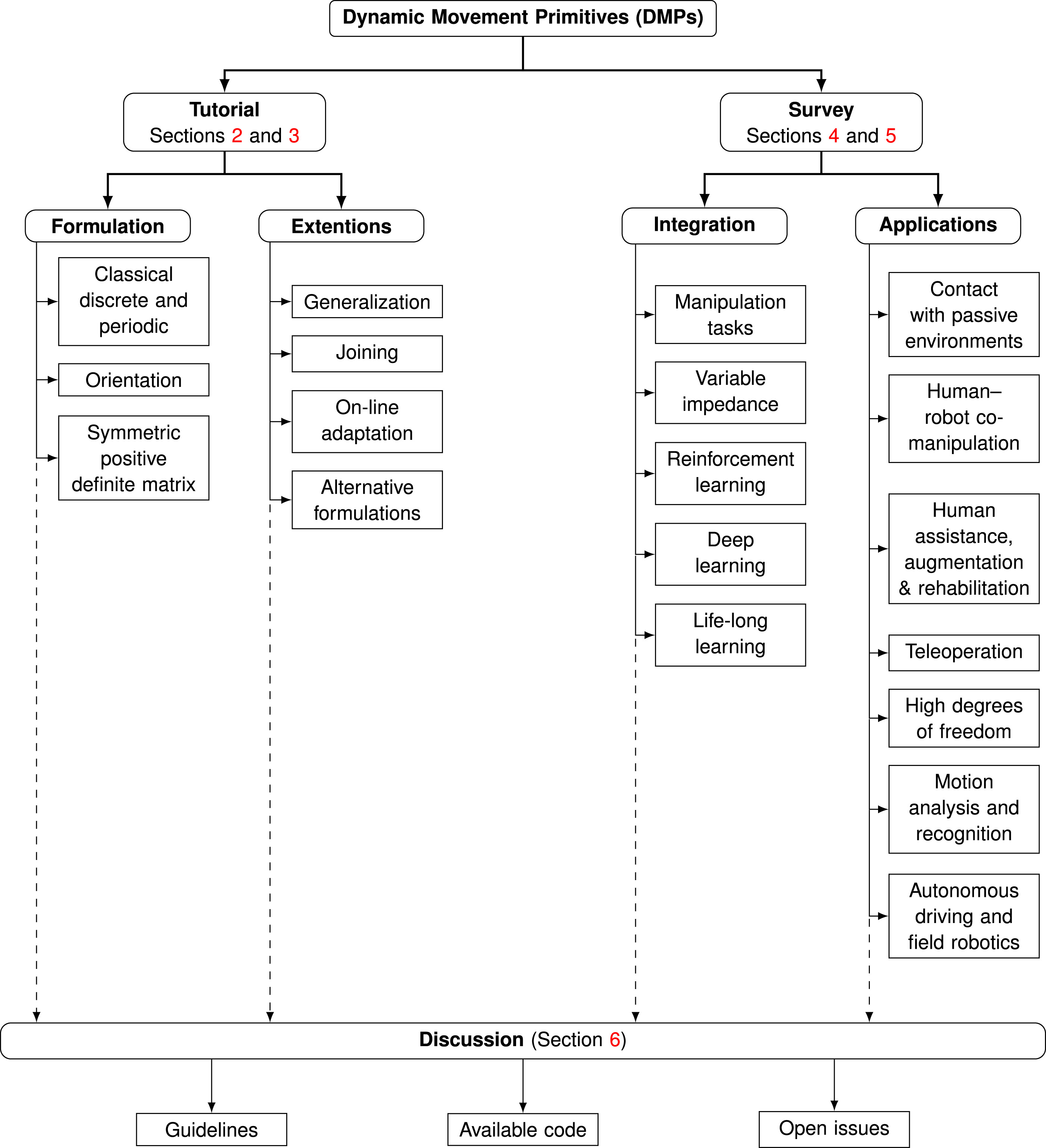
1.4. Contribution overview
2. Formulation of DMP types
| N | ≜ | # of nonlinear basis functions | i | ≜ | index: i = 1, 2, …, N |
| J | ≜ | # of joints or Degree of Freedoms (DoFs) | j | ≜ | index: j = 1, 2, …, J |
| L | ≜ | # of demonstrations or DMPs | l | ≜ | index: l = 1, 2, …, L |
| V | ≜ | # of via-points or via-goals | v | ≜ | index: v = 1, 2, …, V |
| ≜ | # of datapoints | ȷ | ≜ | index | |
| m | ≜ | Dimensions of | n | ≜ | Dimensions of |
| {·}d | ≜ | Subscript for desired value | {·}q or {·}q | ≜ | Quaternion-related variable |
| {·}R or {·}R | ≜ | Rotation matrix-related variable | {·}++, {·}+ or {·}+ | ≜ | SPD-related variable |
| {·}g | ≜ | Subscript for goal value | αz, βz, αx, αs, αg, αyx, αqg | ≜ | Positive gains |
| τ | ≜ | Time modulation parameter | ci, hi | ≜ | Centers and widths of Gaussians |
| T | ≜ | Time duration | t | ≜ | Continuous time |
| λ | ≜ | Forgetting factor | r | ≜ | Amplitude modulation parameter |
| x | ≜ | Phase variable | ≜ | Trajectory data and its 1st derivative | |
| s | ≜ | Sigmoidal decay phase | ≜ | Scaled velocity and acceleration | |
| p | ≜ | Piece-wise linear phase | g, gq, g+ | ≜ | Attractor point (goal) in different spaces |
| ω | ≜ | Angular velocity | , and , | ≜ | Moving target and delayed goal function in different spaces |
| ≜ | Joint position, its 1st time-derivative | gv | ≜ | Intermediate attractor (via-goal) | |
| ≜ | Unit quaternion, its 1st time-derivative | ≜ | Rotation matrix, its 1st time-derivative | ||
| f, fq, fR, fq, | ≜ | Forcing term for different spaces | wi | ≜ | Adjustable weights |
| Ψi | ≜ | Basis functions | θ and ϑ | ≜ | An angle and learnable parameters |
| ≜ | m × m SPD manifold | Symm | ≜ | m × m symmetric matrix space | |
| ≜ | A Riemannian manifold | X | ≜ | An arbitrary SPD matrix | |
| ≜ | A tangent space of at an arbitrary point Λ | M | ≜ | The mean of | |
| ϱ = LogΛ(ϒ) | ≜ | , maps an arbitrary point into | ϒ = ExpΛ(ϱ) | ≜ | , maps into |
| vec (·) | ≜ | A function transforms Symm into using Mandel’s notation. | mat (·) | ≜ | A function transforms into Symm using Mandel’s notation. |
| k, K, , | ≜ | Different forms of stiffness gains | , | ≜ | Different forms of damping gains |
| and | ≜ | Mass and inertia matrices | F, fe, and τe | ≜ | Forces and external forces and torques |
| DMP | Dynamic Movement Primitive | IL | Imitation Learning |
| CMP | Compliant Movement Primitive | UAV | Unmanned Aerial Vehicle |
| RL | Reinforcement Learning | SPD | Symmetric Positive Definite |
| DoF | Degree of Freedom | RBF | Radial Basis Function |
| LWR | Locally Weighted Regression | GMM | Gaussian Mixture Model |
| GMR | Gaussian Mixture Regression | GP | Gaussian Process |
| NN | Neural Network | VMP | Via-points Movement Primitive |
| ProMP | Probabilistic Movement Primitives | LfD | Learning from Demonstration |
| GPR | Gaussian Process Regression | MoMP | Mixture of Motor Primitives |
| EMG | Electromyography | ILC | Iterative Learning Control |
| VIC | Variable Impedance Control | VILC | Variable Impedance Learning Control |
| PI2 | Policy Improvement With Path Integrals | CMA-ES | Covariance Matrix Adaptation-Evolution Strategies |
| CC-DMP | Coordinate Change-DMPs | RBF-NN | Radial Basis Function-Neural Network |
| AL-DMP | Arc-Length-DMP | HRL | Hierarchical RL |
| AEDMP | AutoEncoded DMP | CNN | Convolutional Neural Network |
| GPDMP | Global Parametric Dynamic Movement Primitive | PoWER | Policy Learning by Weighting Exploration with the Returns |
2.1. Discrete DMP
2.1.1. Classical DMP
2.1.1.1. Learning the forcing term
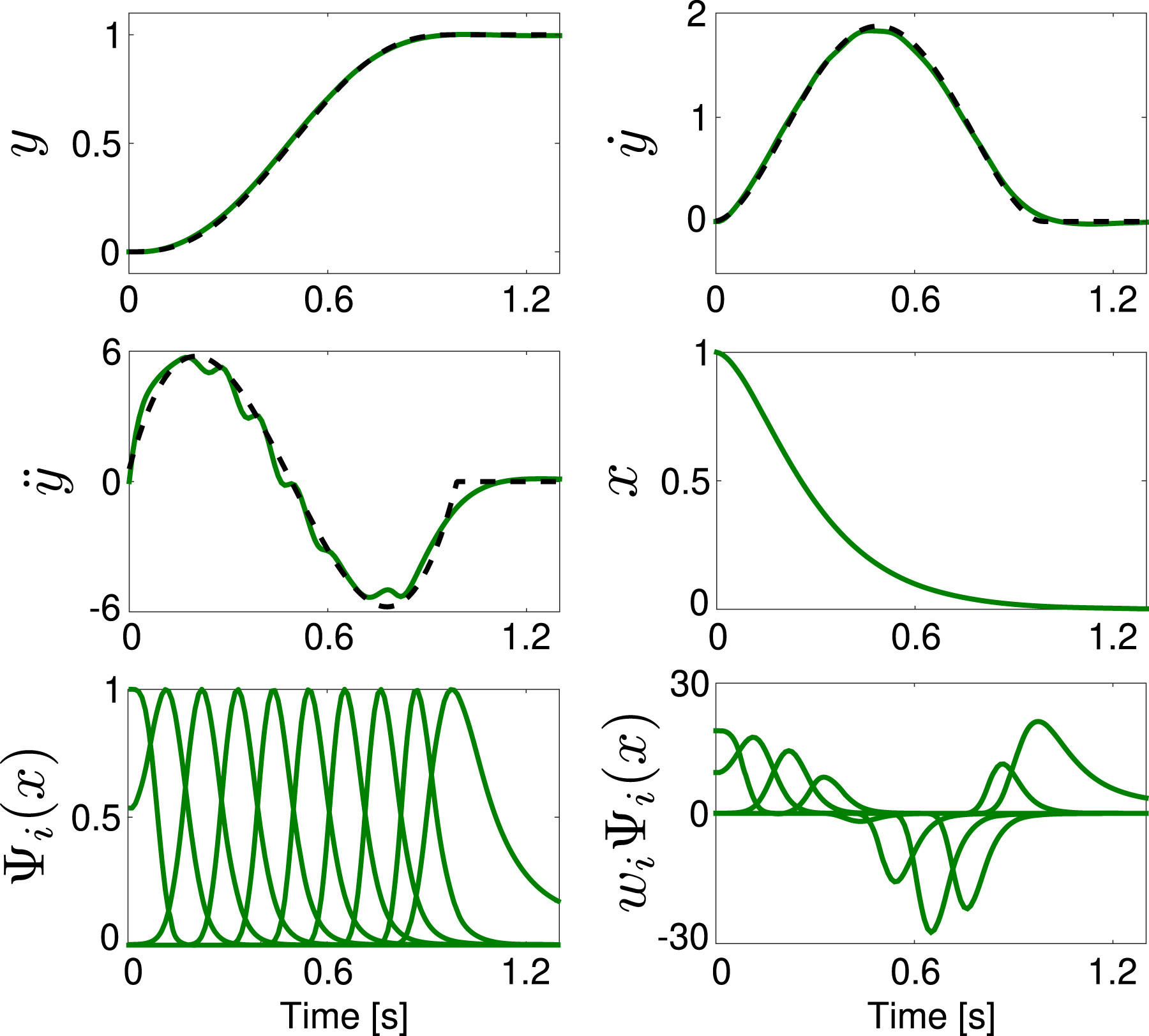
2.1.1.2. Phase stopping and goal switching
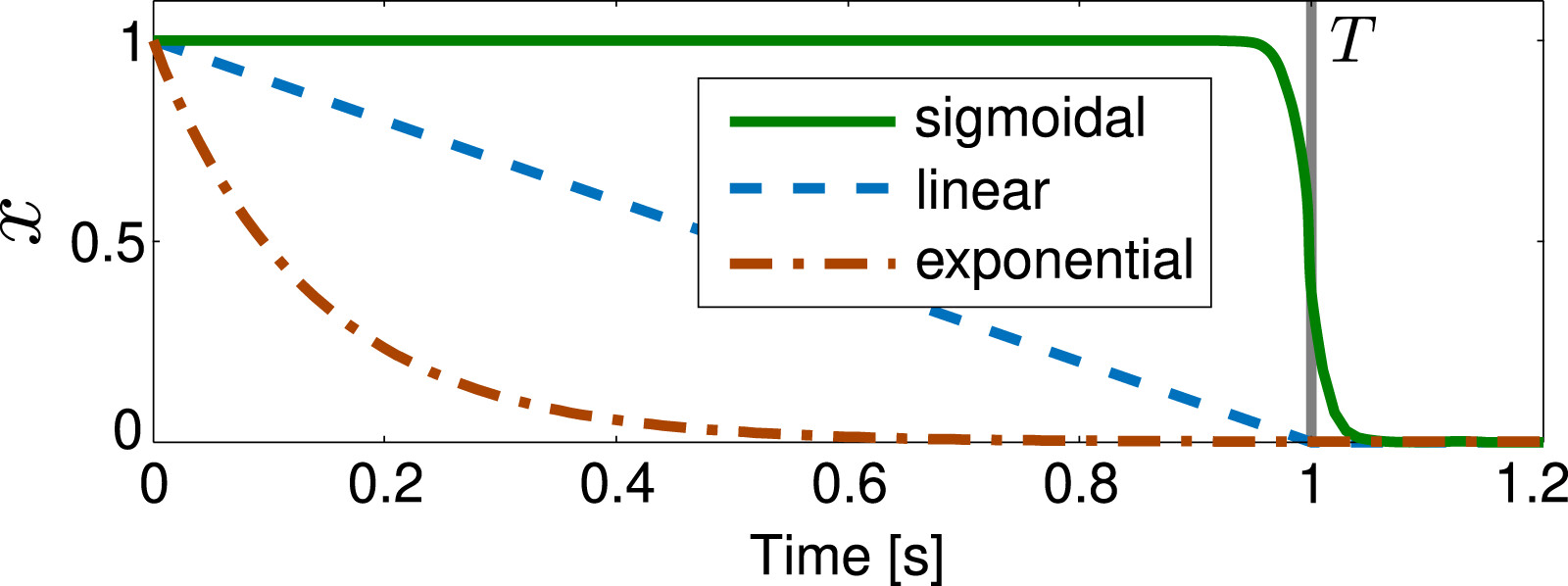
2.1.1.3. Alternative phase variables
2.1.2. Orientation DMP
2.1.2.1. Quaternion DMP
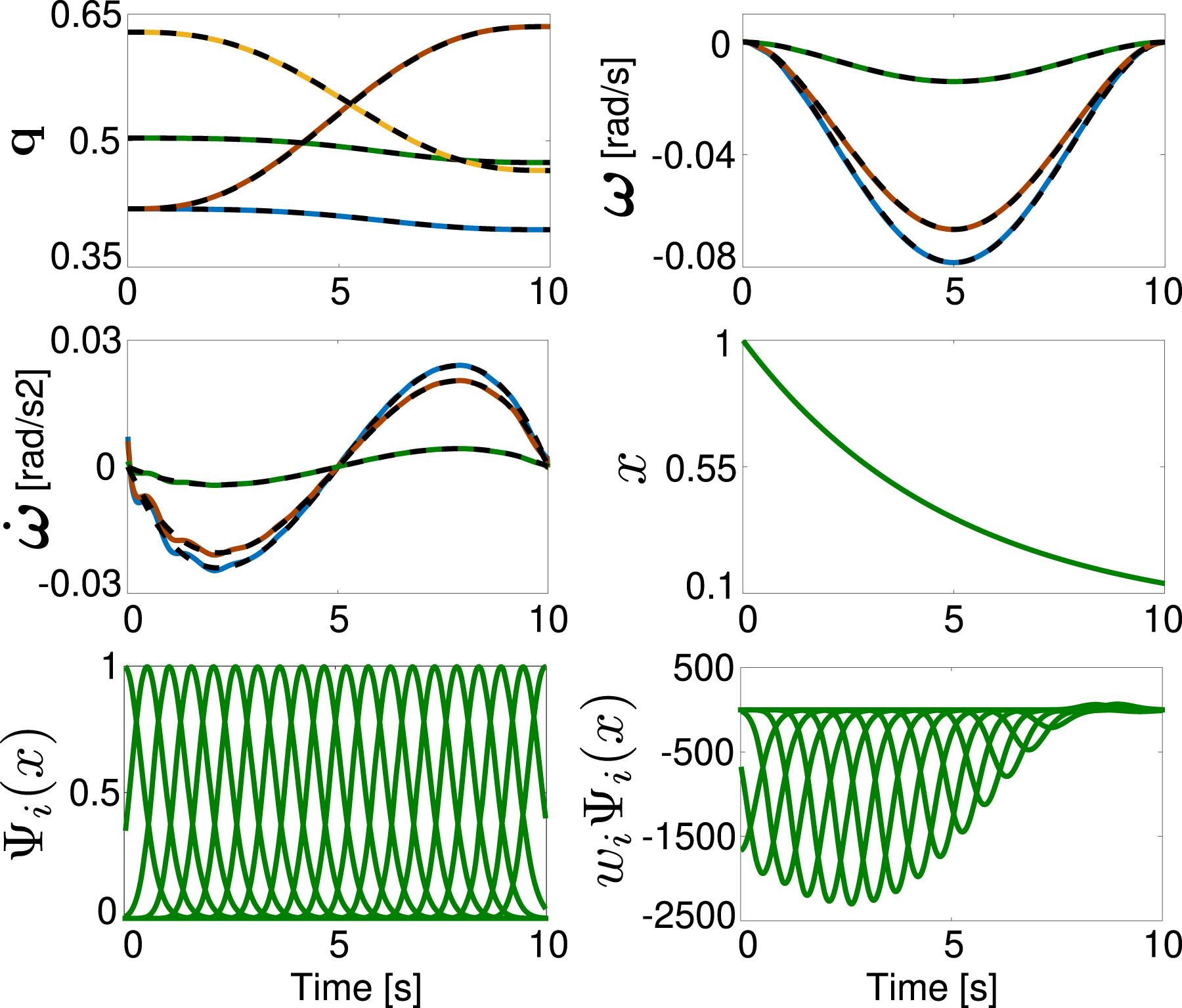
2.1.2.2. Rotation matrix DMP
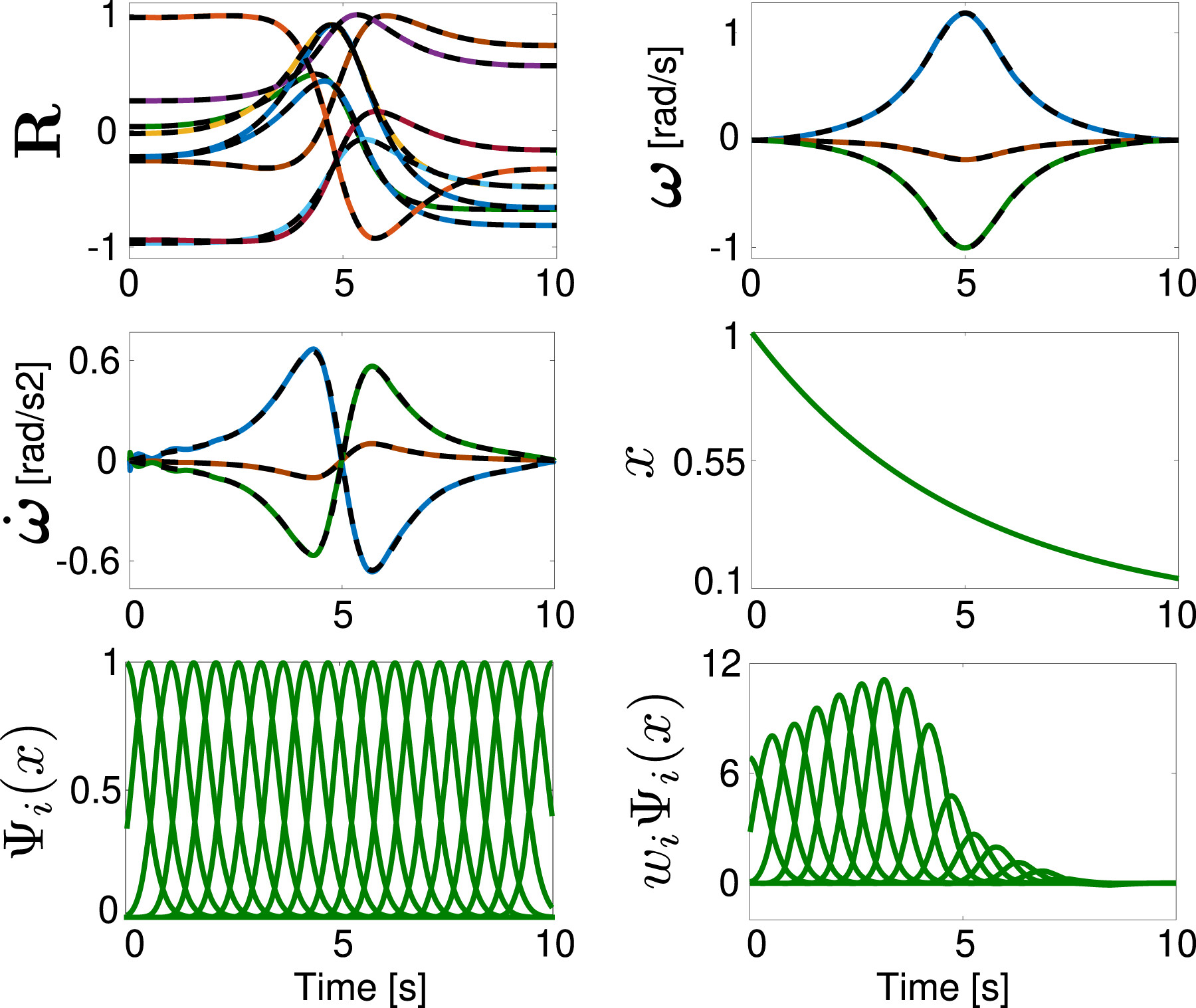
2.1.3. SPD matrices
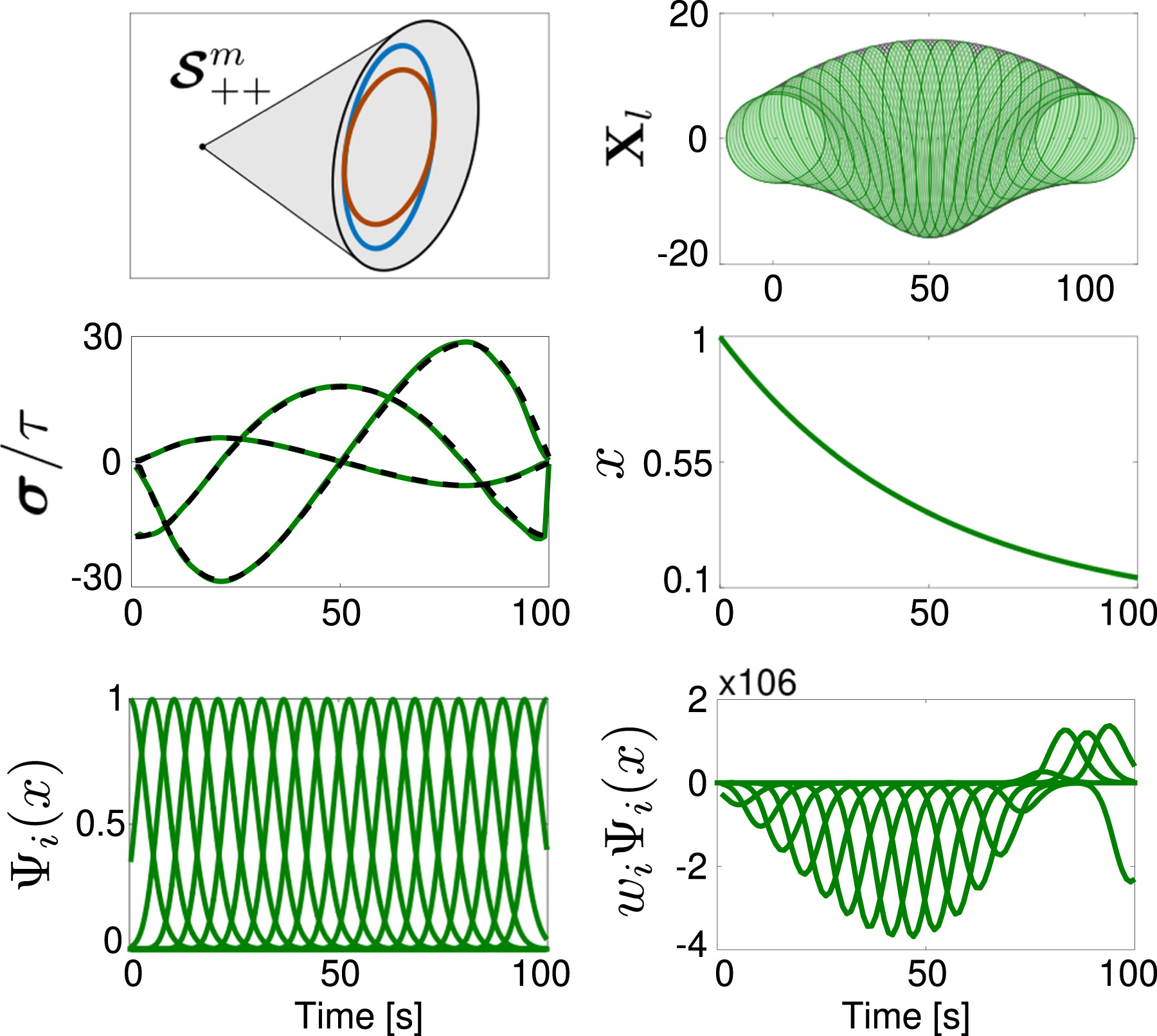
2.2. Periodic DMP
2.2.1. Classical DMP
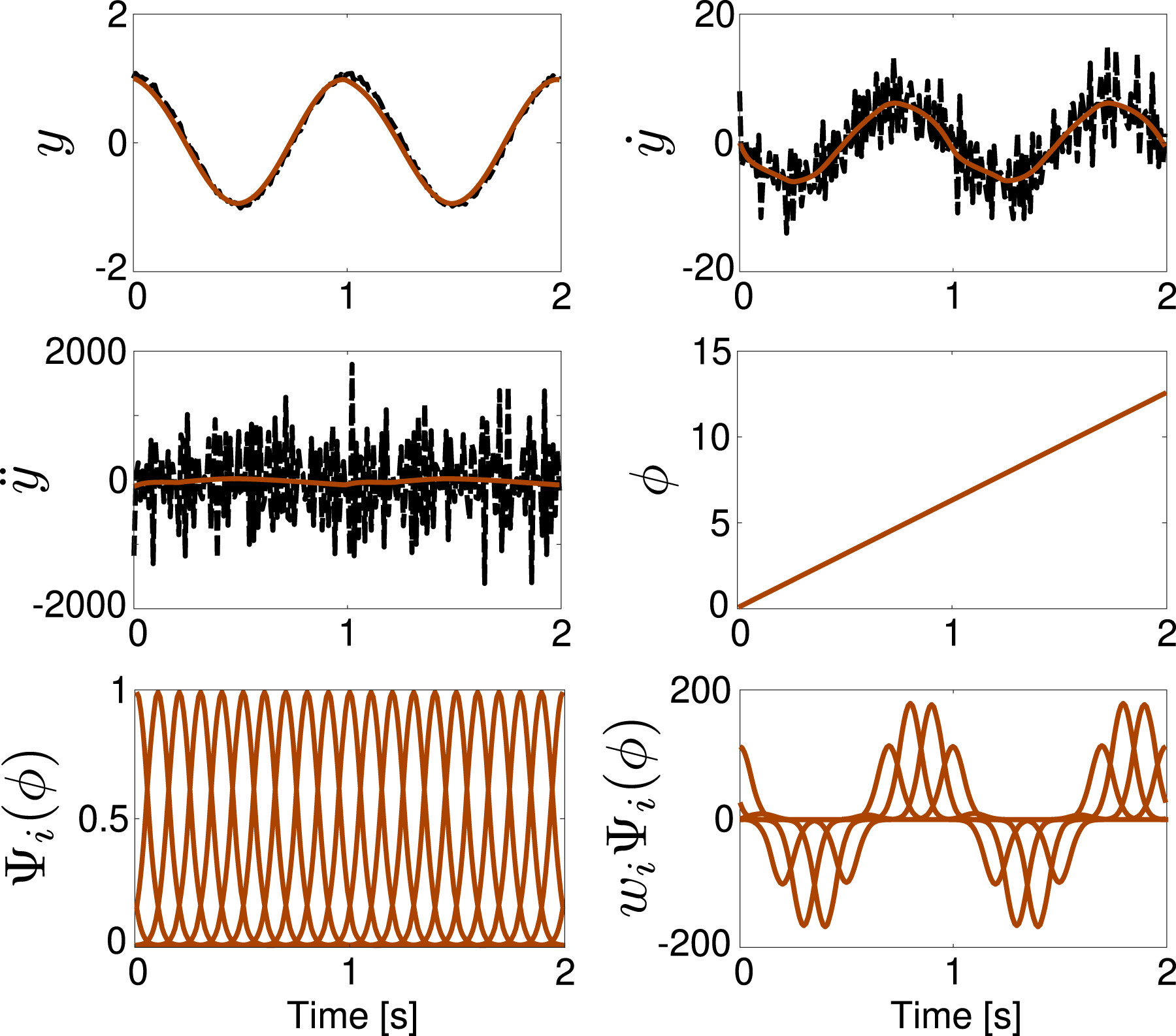
2.2.2. Orientation DMP
2.2.2.1. Quaternion periodic DMP
2.3. Formulation summary
| Type of movement | Space | System of equations | Reference | Short description |
|---|---|---|---|---|
| Discrete | Equations (1)–(3) (Ijspeert et al., 2002c) | A single DoF, discrete motion trajectory is encoded into a linear, second-order dynamical system with an additive, nonlinear forcing term. Convergence to the desired goal g is ensured by a vanishing phase variable x. | ||
| + fq (x) | Equations (16) and (17) (Abu-Dakka et al., 2015a) | A quaternion-based orientation trajectory (3 DoFs) is encoded into a second-order dynamical system with an additive, nonlinear forcing term. The error definition complies with the geometry of the unit quaternion space. | ||
| Equations (23) and (24) (Ude et al., 2014) | A rotation matrix-based orientation trajectory (3 DoFs) is encoded into a second-order dynamical system with an additive, nonlinear forcing term. The error definition complies with the geometry of the rotation matrices space. | |||
| Equations (29) and (30) (Abu-Dakka and Kyrki, 2020) | An SPD matrices trajectory, m (m + 1)/2 DoFs, is encoded into a second-order dynamical system with an additive, nonlinear forcing term. The error definition complies with the geometry of the SPD matrices space. | |||
| Periodic | Equations (34)–(36) (Ijspeert et al., 2002b) | A single DoF, periodic motion trajectory is encoded into a linear, second-order dynamical system with an additive, nonlinear forcing term. The resulting system generates a stable limit cycle. | ||
| Equations (43) and (44) (Abu-Dakka et al., 2021) | A quaternion-based orientation trajectory (3 DoFs) is encoded into a second-order dynamical system with an additive, nonlinear forcing term. The error definition complies with the geometry of the unit quaternion space. |
3. DMP extensions
3.1. Generalization
3.1.1. Start, goal, and scaling
3.1.2. Via-points
3.1.3. Task parameters
3.2. Joining multiple DMPs
| Approach | Author | Language | Description |
|---|---|---|---|
| Discrete DMP | Fares J. Abu-Dakka | C++ | An implementation for discrete DMP based on the work in Abu-Dakka et al. (2015a) and Ude et al. (2010, 2014). |
| Periodic DMP | Luka Peternel | Python | An implementation for periodic DMP based on the work in Peternel et al. (2016). |
| Unit quaternion DMP | Fares J. Abu-Dakka | MATLAB and C++ | An implementation for unit quaternion DMP and goal switching based on the work in Abu-Dakka et al. (2015a) and Ude et al. (2014). |
| SPD DMP | Fares J. Abu-Dakka | MATLAB | An implementation for SPD DMP and goal switching based on the work in Abu-Dakka and Kyrki (2020). |
| Joining DMPs | Matteo Saveriano | MATLAB | An implementation for joining multiple DMPs based on the work in Saveriano et al. (2019). |
| Coupling-force DMPs | Aljaz Kramberger | MATLAB | An implementation for discrete DMPs and force coupling terms based on the work in Kramberger et al. (2018). |
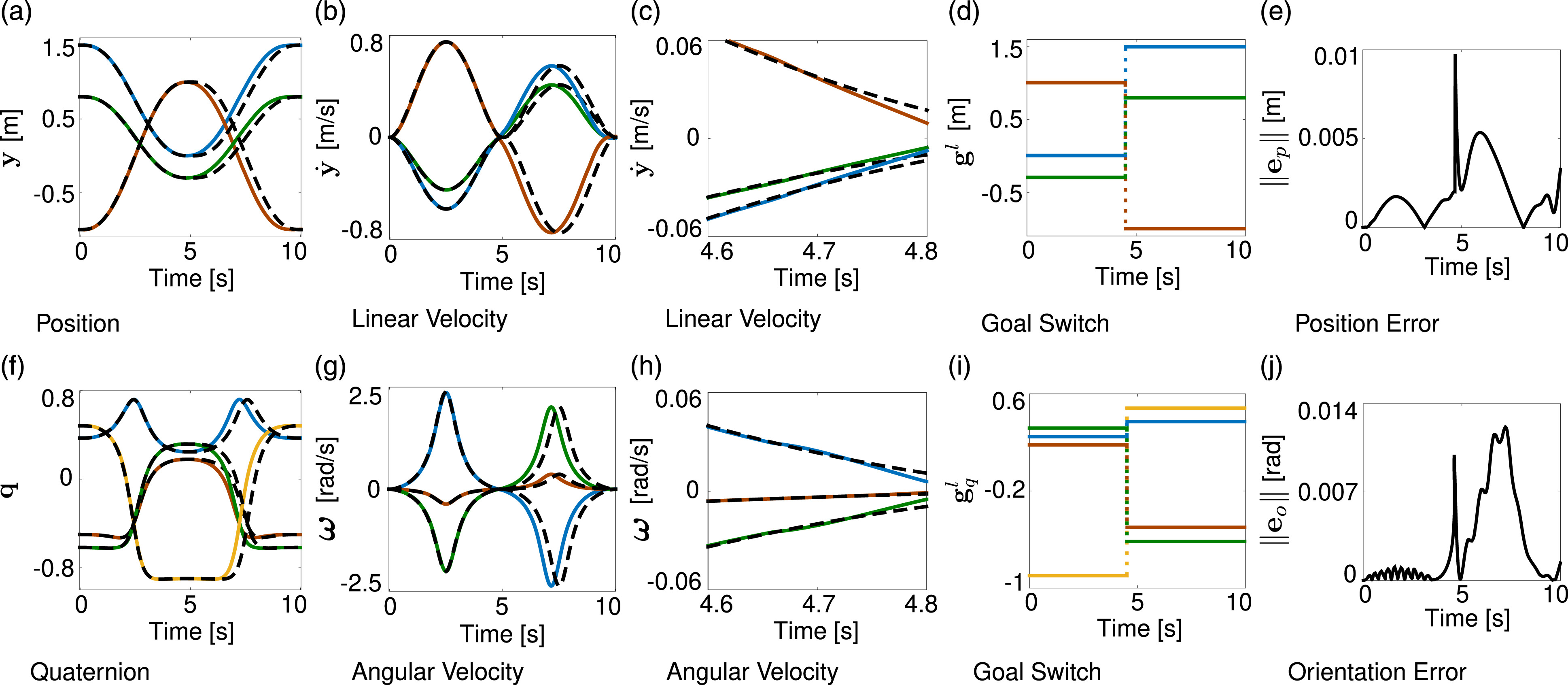
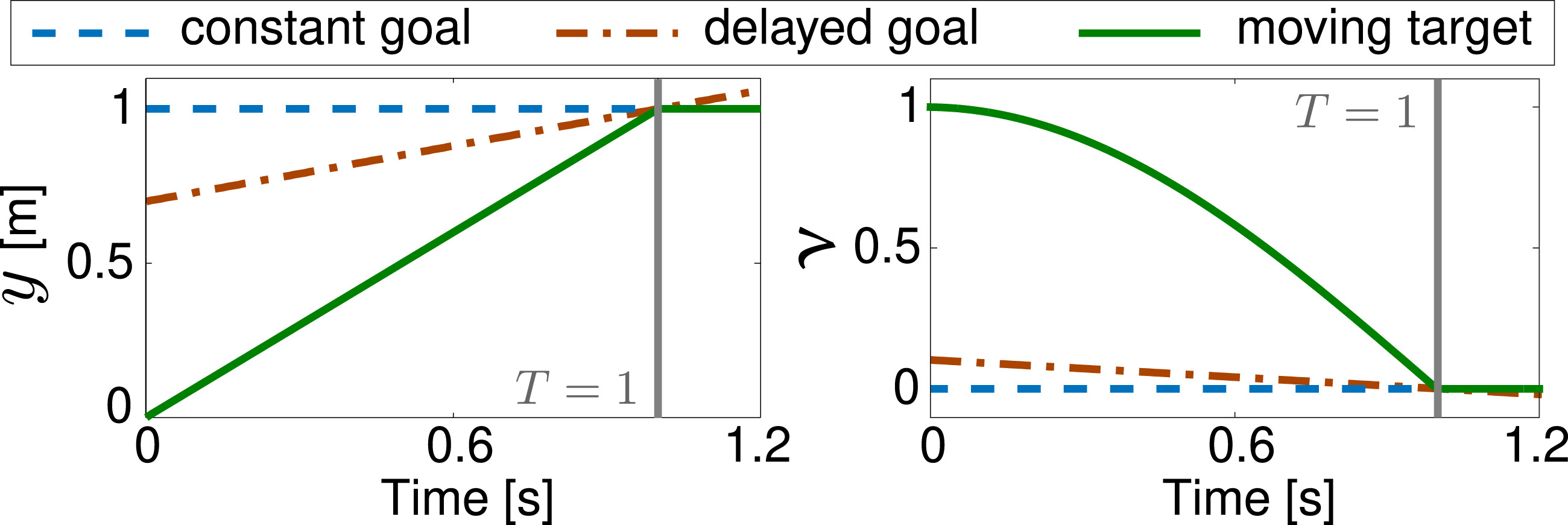
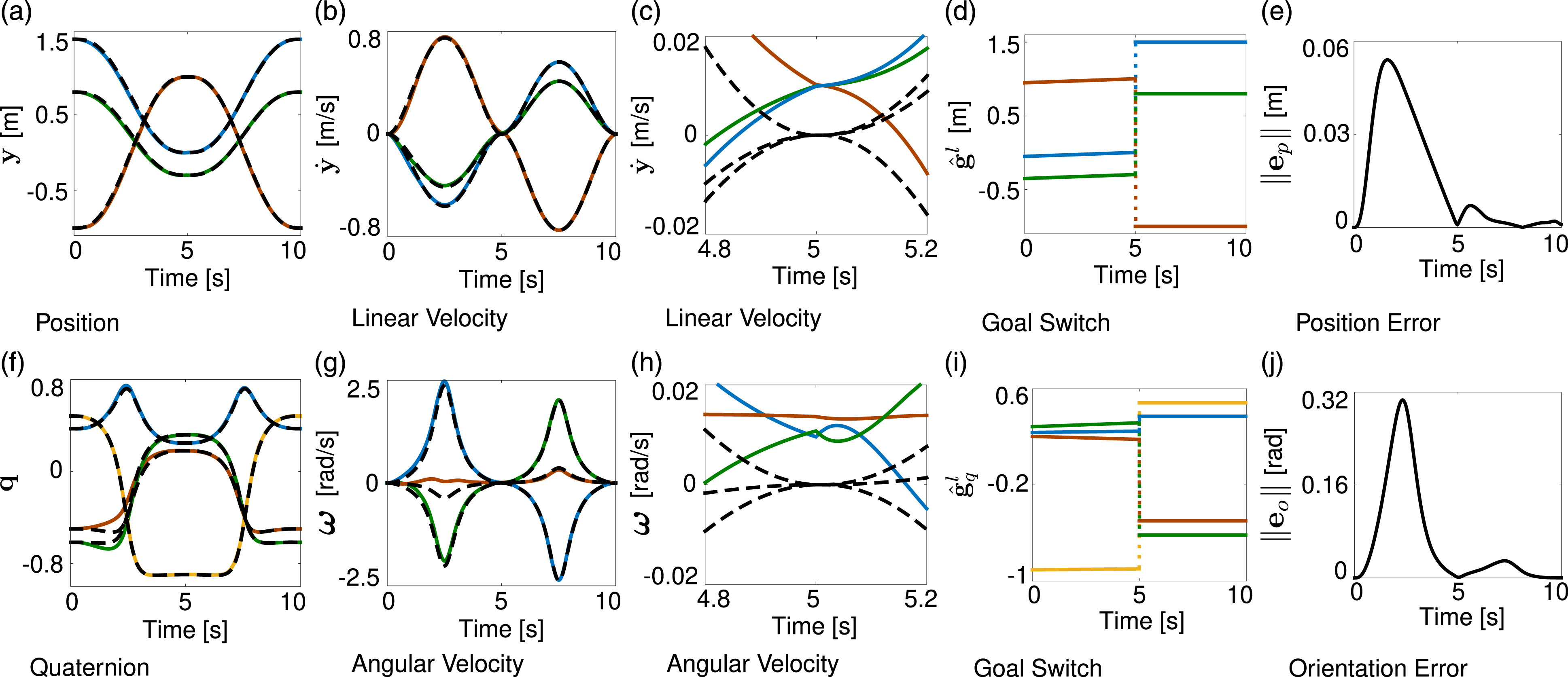
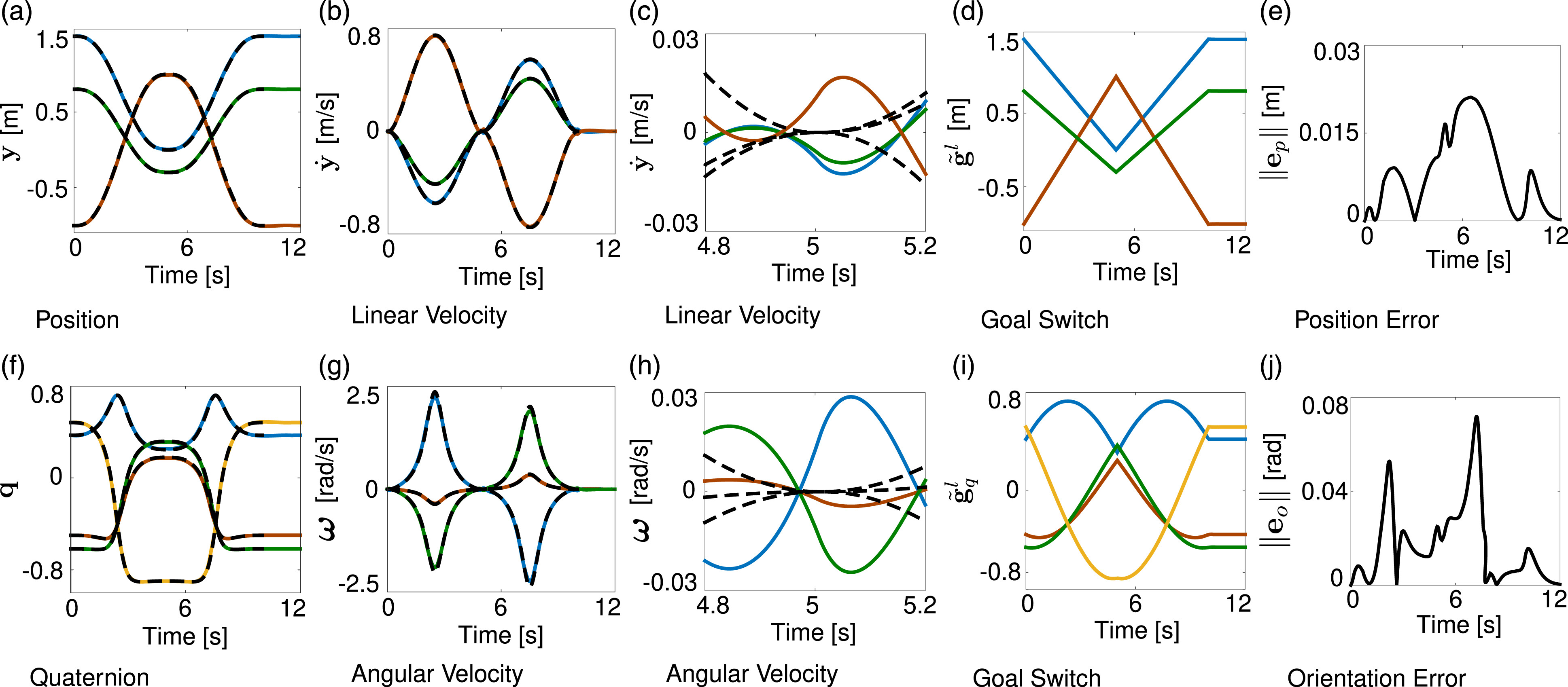
3.2.1. Velocity threshold
3.2.2. Target crossing
3.2.3. Basis functions overlay
3.3. Online adaptation
3.3.1. Robot obstacle avoidance and coaching
3.3.2. Robot adaptation based on force feedback
3.3.3. Exoskeleton joint torque adaptation
3.3.4. Trajectory adaptation based on reference velocity
3.4. Robots with flexible joints
3.5. Alternative formulations
4. DMPs integration in complex frameworks
4.1. Manipulation tasks
4.1.1. Grasping and tool usage
4.1.2. Motion primitives sequencing
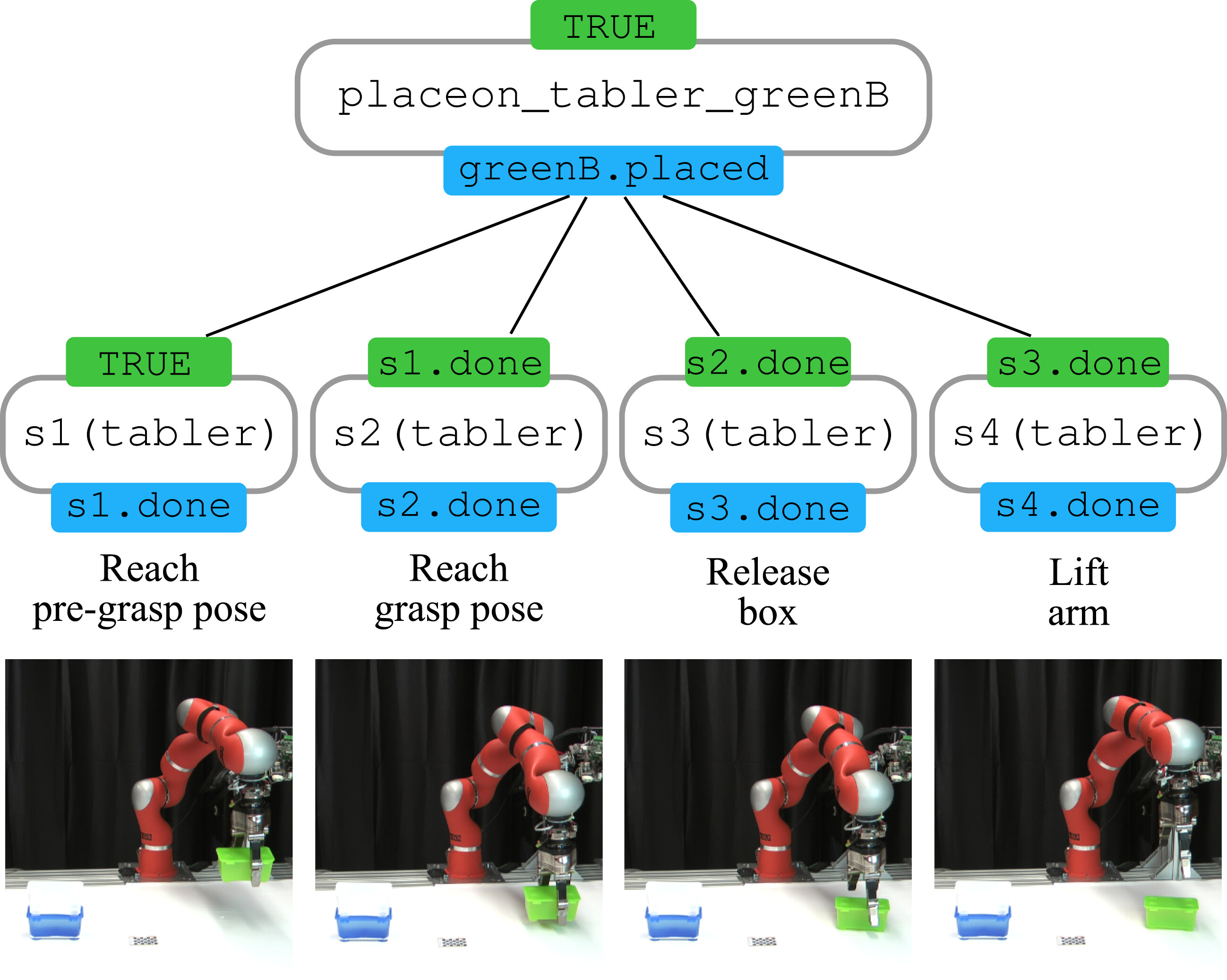
4.1.3. Data collection
4.1.4. Task learning and execution
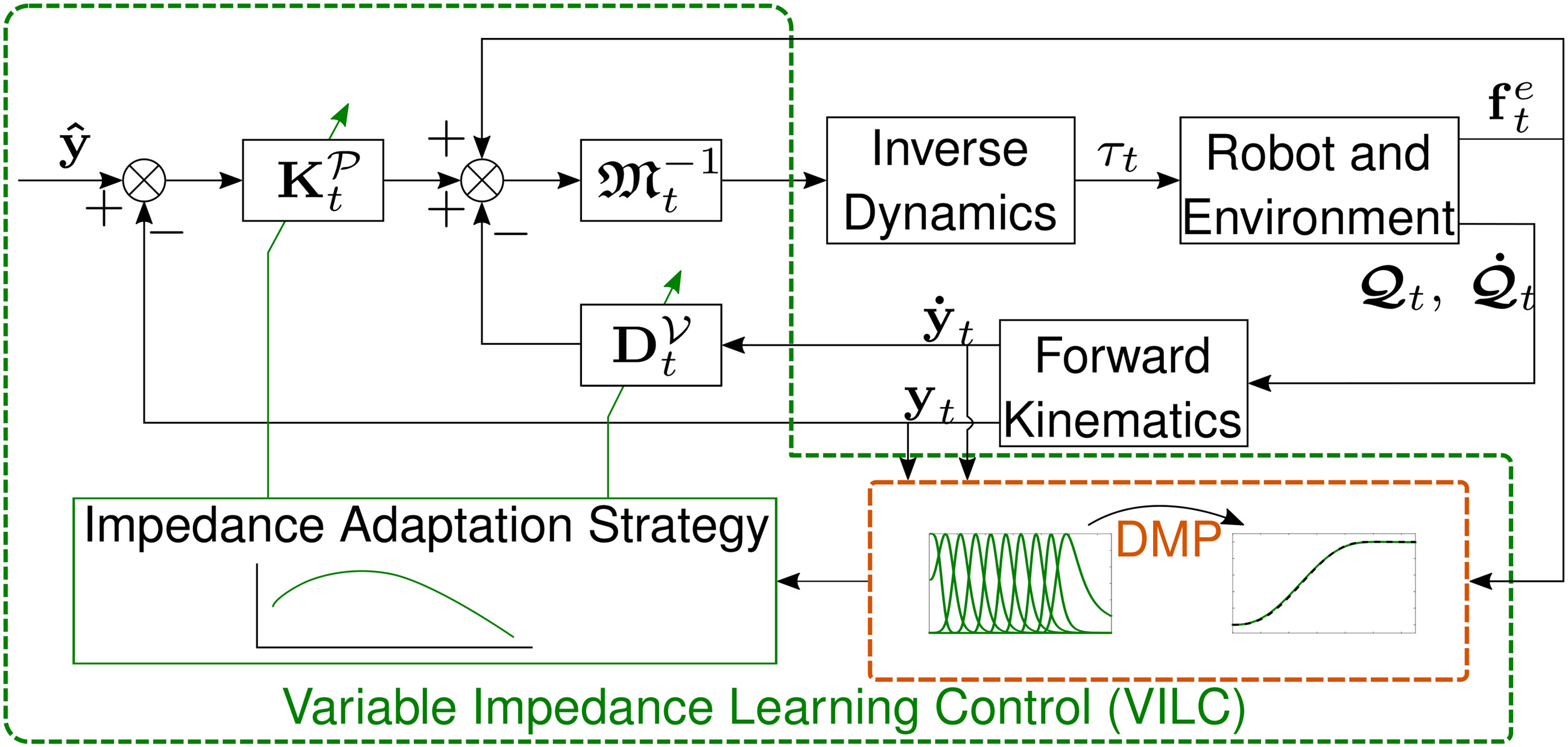
4.2. Variable impedance learning control
4.3. Reinforcement Learning (RL)
4.3.1. DMPs as control policies
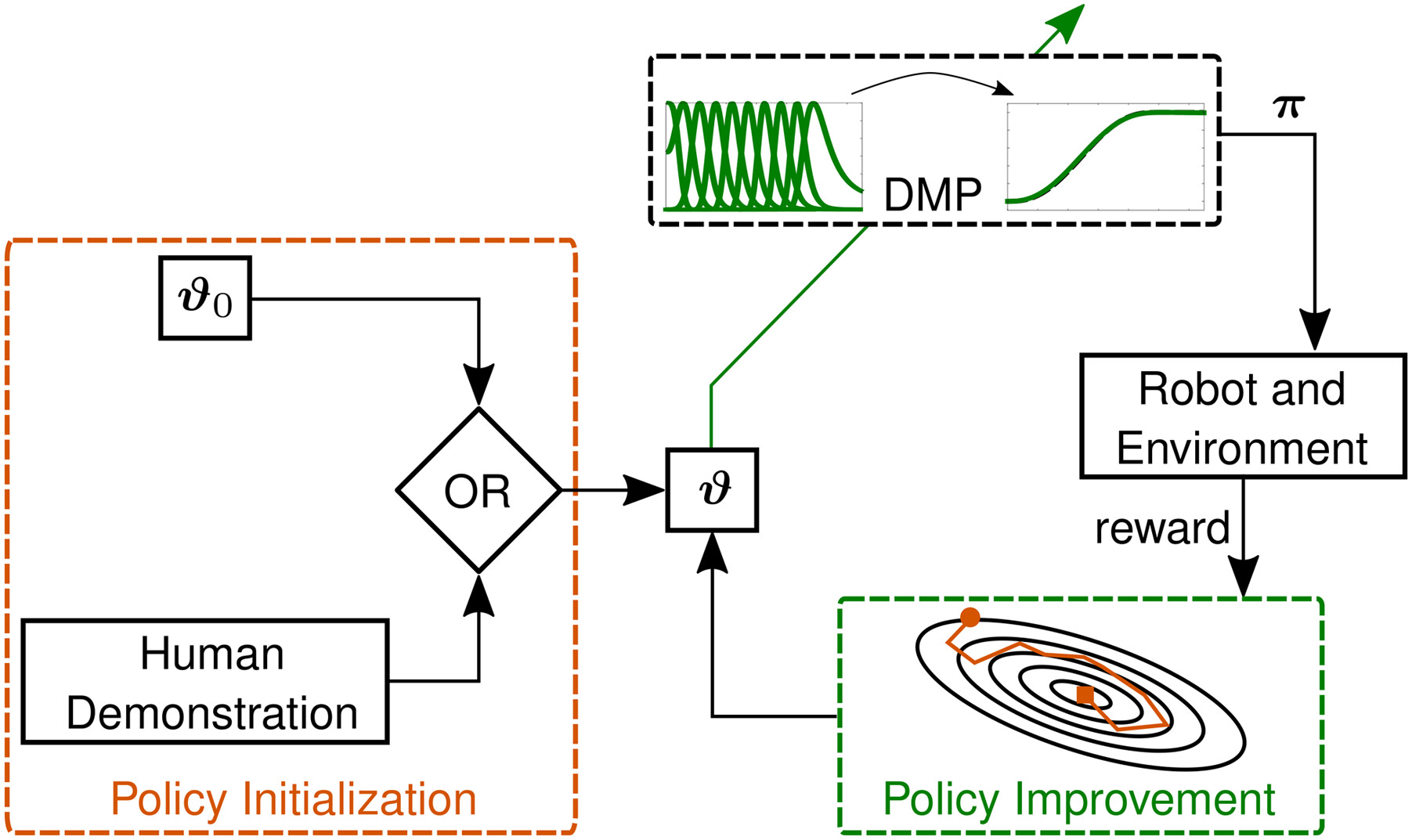
4.3.2. Limit the search space
4.3.3. DMP generalization and sequencing
4.3.4. Skills transfer
4.3.5. Learning hierarchical skills
4.4. Deep learning
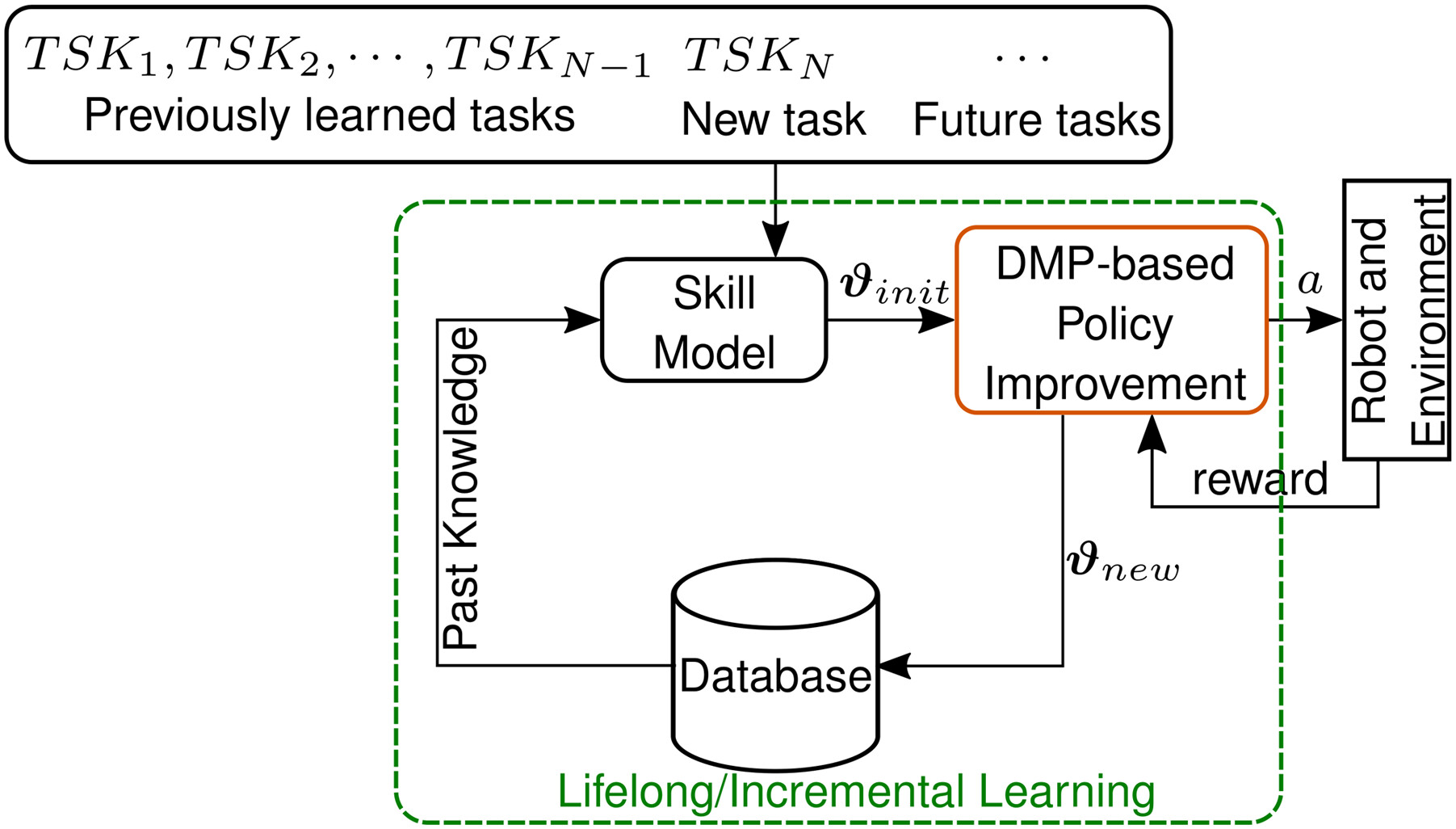
4.5. Lifelong/Incremental learning
5. DMPs in application scenarios
5.1. Robots in contact with passive environment
5.1.1. Demonstration of interaction tasks


5.1.2. Assembly tasks

5.1.3. Learning methods for contact adaptation
5.2. Human–robot co-manipulation

5.3. Human assistance, augmentation, and rehabilitation

5.4. Teleoperation
5.5. High DoF robots

5.6. Motion analysis and recognition
5.7. Autonomous driving and field robotics
6. Discussion
| Limitation | Related work | Status |
|---|---|---|
| Via-points | Ning et al. (2011, 2012), Weitschat and Aschemann (2018), Saveriano et al. (2019), and Zhou et al. (2019) | ✓ |
| Start-point | Hoffmann et al. (2009), Ijspeert et al. (2013), Weitschat et al. (2013), and Dragan et al. (2015) | ✓ |
| Goal-point | Ijspeert et al. (2013), Weitschat et al. (2013), Abu-Dakka and Kyrki (2020), Dragan et al. (2015), and Weitschat and Aschemann (2018) | ✓ |
| Obstacle avoidance | Park et al. (2008), Hoffmann et al. (2009), Tan et al. (2011), Kim et al. (2015), and Rai et al. (2017) | ✓ |
| Geometry-constrained data | Pastor et al. (2009), Abu-Dakka et al. (2015a), Ude et al. (2014), Saveriano et al. (2019), and Abu-Dakka and Kyrki (2020) | ❙5 |
| Probabilistic | Ben Amor et al. (2014) | ❙ |
| Extrapolation | Pervez and Lee (2018) and Zhou et al. (2019) | ❙ |
| High-dim input | Pervez et al. (2017a) and Pahič et al. (2020) | ❙ |
| Closed-loop | Peternel et al. (2016) and Kramberger et al. (2018) | ❙ |
| Multi-attractor | Nemec et al. (2018) and Iturrate et al. (2019) | ❙ |
6.1. Guidelines for different applications
6.1.1. Discrete versus periodic
6.1.2. Space representation
6.1.3. Weights learning method
6.1.4. Online adaptation
6.1.5. Impedance versus force
6.2. Resources and codes
6.3. Limitations and open issues
6.3.1. Implicit time dependency
6.3.2. Stochastic information
6.3.3. Closed-loop implementation and issues
6.3.4. Coping with high-dimensional inputs
6.3.5. Multi-attractor systems
7. Concluding remarks
Acknowledgments
Declaration of conflicting interests
Funding
ORCID iDs
Footnotes
References
Cite
Cite
Cite
Download to reference manager
If you have citation software installed, you can download citation data to the citation manager of your choice
Information, rights and permissions
Information
Published In

Keywords
Rights and permissions
Authors
Metrics and citations
Metrics
Journals metrics
This article was published in The International Journal of Robotics Research.
View All Journal MetricsPublication usage*
Total views and downloads: 17655
*Publication usage tracking started in December 2016
Altmetric
See the impact this article is making through the number of times it’s been read, and the Altmetric Score.
Learn more about the Altmetric Scores
Publications citing this one
Receive email alerts when this publication is cited
Web of Science: 142 view articles Opens in new tab
Crossref: 181
- Review and perspectives on multimodal perception, mutual cognition, and embodied execution for human–robot collaboration in Industry 5.0
- A Review on Environment-Adaptive Gait Planning for Semiautonomous Lower Limb Exoskeletons
- Robust Co-Adaptive Human–Robot Interaction Under Sensor Noise, Delay, and Parameter Drift
- Master-slave dual-arm learning from demonstration assembly based on modified triple reversible dynamic motion primitives
- Cooperative task spaces for multi-arm manipulation control based on similarity transformations
- FRMD: fast robot motion diffusion via trajectory-level consistency distillation
- Proceedings of the 31st International Conference on Intelligent User Interfaces
- A survey on imitation learning for contact-rich tasks in robotics
- ROPE: a novel method for real-time phase estimation of complex biological rhythms
- Volumetric Obstacle Avoidance Based on Dynamic Movement Primitives for Robot Path Planning in Human–Robot Collaboration
- View More
Figures and tables
Figures & Media
Tables
View Options
View options
PDF/EPUB
View PDF/EPUBAccess options
If you have access to journal content via a personal subscription, university, library, employer or society, select from the options below:
I am signed in as:
View my profileSign out

I can access personal subscriptions, purchases, paired institutional access and free tools such as favourite journals, email alerts and saved searches.
loading institutional access options
IOM3 members can access this journal content using society membership credentials.
IOM3 members can access this journal content using society membership credentials.
Alternatively, view purchase options below:
Purchase 24 hour online access to view and download content.
Access journal content via a DeepDyve subscription or find out more about this option.
