But how does the speaker’s sound (or voice) shape perceptions of the object that is spoken about? While prior work on human-to-human communication suggests that people make rapid inferences about the person speaking (
McAleer, Todorov, and Belin 2014), it is less understood how these perceptions spill over to the focal object the speaker refers to. We know from previous work that using a female versus male speaker in radio advertisements can elicit gender-stereotypical attributes that lead to better recall performance of the advertisement (e.g., a female vs. male actor advertising a feminine product leads to better recall of that advertised product [
Hurtz and Durkin 2004]). However, a significant disadvantage for brands arises from the necessity to engage trained human voice actors who can effectively match the envisioned properties of the brand or product. For firms, this necessity often negatively affects the time, money, and complexity in traditional advertisement settings (
Erdogan 1999;
Stafford, Stafford, and Day 2002).
The current article takes a different route by examining how AI-generated voices can be intentionally designed to enhance more positive product congruency perceptions and downstream advertising performance. This question is particularly timely given the widespread adoption of AI-powered voice technologies such as Amazon Alexa and Google Home, which are quickly becoming the “vocal touchpoints” between consumers and firms (
Hildebrand et al. 2020;
Zierau et al. 2022). With recent advances in speech synthesis, AI-powered voice technologies have become more sophisticated, leading consumers to ascribe more anthropomorphic properties to these agents (
Payr 2013), attributing the experience of emotions (
Jesin, Watson, and MacDonald 2018), personalities (
Rubin 2017), and even gender stereotypes (
Tolmeijer et al. 2021).
The current article goes beyond attributions of humanlikeness, general acceptance, or whether consumers believe these agents experience emotions. Specifically, we illuminate whether consumers develop unique mental representations of perceived physicality (e.g., how heavy and tall users envision the conversational agent). This is especially important given the pivotal role physicality plays in interpersonal perception. For instance, taller people tend to be rated higher in leadership ability (
Lindqvist 2012), perceived competence (
Chateau et al. 2005), social attractiveness (
Stulp et al. 2015), and professional status (
Jackson and Ervin 1992). It is virtually unknown how the artificial voices of conversational agents should be designed at the vocal feature level to shape product and brand perceptions (for a review of prior work, see
Table 1). Therefore, this article takes a critical first step in altering a key vocal feature in conversational agents to shape users’ perceptions of physicality and the downstream impact of such design decisions on consumers and firms.
We focus on one key vocal feature that determines differences in body size perception in humans: “vocal tract length” (VTL), which is measured as the distance from the vocal folds to the lips (
Lammert and Narayanan 2015) and varies as a function of body size, with larger bodies typically corresponding to longer vocal tracts (
Fitch 1997). While conversational agents lack a physical VTL, recent advances in speech synthesis offer the opportunity to directly alter the digital VTL of artificially generated voices by mimicking the filtering process of the formant frequencies that naturally occur in the human vocal tract (Amazon 2020). In the current research, we examine how differences in the digital VTL of a conversational agent shape physicality attributions toward that agent and how those attributions in turn impact consumers’ perceptions of products along with the downstream effects on advertising performance.
In what follows, we provide an integrative review of prior work on the impact of voice interactions on consumers and how they can influence the user experience with conversational agents, the role of digital VTL in physicality perceptions, and the link between sound symbolism and congruency effects in marketing. We then provide evidence from four studies, including one large-scale field experiment, that test our theorizing. We conclude with a discussion on how speech synthesis and artificial voice generation provide novel directions for future research in voice marketing.
Theoretical Background
Toward a Vocal Feature Driven Approach to Consumer–Voice Assistant Interactions
With the growing adoption of conversational agents by firms as part of their digital marketing efforts, new vocal touchpoints have emerged for consumers (
Capgemini 2019;
Hartmann, Bergner, and Hildebrand 2023;
Hildebrand, Hoffman, and Novak 2021;
Hu et al. 2022). The emerging literature on consumer–voice assistant interactions has predominantly explored differences in modality that impact consumers; that is, how voice-based interactions alter consumer behavior compared with other modalities (e.g., text-based interactions; see
Zierau et al. 2022). For example, voiced search (vs. typed search) has been linked to reduced purchase intentions due to a decreased action-oriented mindset (
King, Auschaitrakul, and Lin 2022), and consumers tend to use more concrete language due to concerns of being misunderstood (
Melumad 2023). Relatedly, presenting product choices through a voice-based (vs. text-based) interaction can increase cognitive difficulty in information processing, leading to detrimental effects for consumers (
Munz 2020; for a more detailed review on the effects of interacting with different modalities, see
King, Auschaitrakul, and Lin [2022]). However, enhancing the verbal abilities of conversational agents, such as increasing the extent of signaling mutual understanding or grounding, can lead to more intimate consumer–brand interactions (
Bergner, Hildebrand, and Häubl 2023).
Despite these recent developments on consumer–voice assistant interactions, only a fraction of prior work focused on altering the vocal features of artificially generated voices to shape user perception and behavior (for a detailed review, see
Table 1). For example, prior work revealed that an artificial female voice with increased pitch is perceived as having better social skills and a more pleasant personality (
Niculescu et al. 2013) and that an artificial female voice with increased speech rate is often perceived as more outgoing (
Lee et al. 2019). However, the same vocal feature manipulation of increased speech rate can also elicit negative attributions, such that masculine robots are perceived as less emotionally stable and more nervous with an increasing number of words per minute (
Lee et al. 2019). Early work on emotional speech in social robotics and human–robot interactions also revealed that increasing pitch variability with a faster speech rate makes people believe a robot is happier compared with reduced pitch variability and a slower speech rate (
Breazeal 2001;
Crumpton and Bethel 2016).
In summary, most prior work has examined either modality effects on consumer–voice assistant interactions (i.e., voice vs. text) or more basic vocal features to alter the assistant’s gender or discrete emotions (
Tolmeijer et al. 2021). Building on and extending this prior work to a more marketing-relevant domain, we examine how one unexplored feature that is known to alter physicality attributions in humans (i.e., VTL) impacts consumer evaluations of product congruency and downstream consequences on advertising performance. As discussed in the “Overview of Studies and Speech-Synthesis Paradigm” section, we also hold gender constant and vary only one feature of interest (i.e., VTL) in a single conversational agent (as opposed to developing distinct voices for different types of voice assistants). This offers a unique possibility to shift the perception of the same conversational agent; something that is impossible in human speakers due to the physical preconditions of the individual.
VTL, Physicality, and Masculinity Attributions
Although physicality is typically gleaned visually, the bioinformational dimensions theory suggests that the human voice contains markers signaling physicality (i.e., body size;
Xu, Kelly, and Smillie 2013). The most important feature that relates to speakers’ vocal expression of physicality is the VTL (
Fitch 2000). Perceptually, VTL influences the vocal timbre such that people with longer (shorter) VTL are rated as physically larger (smaller) (
Ives, Smith, and Patterson 2005;
Puts, Gaulin, and Verdolini 2006). Such perceptions of physicality lead to subsequent inferences regarding the level of masculinity, with larger perceived body size often linked to higher perceived masculinity (
Holzleitner et al. 2014).
At a physiological acoustic level, VTL filters the source signal and “encourages” the formation of certain frequencies while discouraging others (
Fitch 1994). Specifically, longer (shorter) vocal tracts encourage the formation of lower (higher) formant frequencies (
Fitch 1994,
2006;
Frey and Gebler 2010), altering in turn perceptions of physicality (
Feinberg et al. 2011). Compared with other vocal features indicating physical size (e.g., pitch;
Pisanski et al. 2016), VTL elicits higher ratings of physical dominance (
Puts et al. 2007) regardless of the underlying pitch (
Pisanski, Anikin, and Reby 2022). VTL is also a more reliable marker to infer body size, particularly within the same gender (
Pisanski et al. 2014), and it is more difficult for humans to change intentionally. This is because VTL is largely determined by the size of the skull, which is in turn closely affected by body size (
Fant 1971). Different research streams have examined the nuanced role of individuals’ VTL, with recent work demonstrating that voice alterations due to differences in the VTL can even impact perceptions and decision making of a board of directors, leading to higher compensations for CEOs with a longer VTL (
Nair, Haque, and Sauerwald 2021).
The bioinformational dimensions theory is also consistent with evolutionary perspectives, as our brains have evolved to allow us to rapidly make associations between elements of our environment that promote survival and the ability to procreate (
Fox 1992). We can detect the size of an unseen animal based on the sound of its roar (
Raine et al. 2018) or rapidly assess a stranger's personality traits based on their vocal features (
McAleer, Todorov, and Belin 2014). Such vocalization inferences play a vital role in a wide variety of species; for example, birds chirp to attract mates (
Eriksson and Wallin 1986) and lions roar to deter rivals (
Funston et al. 1998). In humans, certain vocal features add nuance to verbal expression and reveal much about a speaker, including information about their emotional state (
Scherer 2003), personality (
Polzehl, Möller, and Metze 2010), gender (
Titze 1989), and age (
Taylor and Reby 2010; for a review, see
Hildebrand et al. [2020]).
For illustrative purposes, we extracted short speaker excerpts from two known, male actors who differ in body size: Kevin Hart (height: 1.65 m, weight: 60 kg) and Dwayne “The Rock” Johnson (height: 1.96 m, weight: 119 kg). We then used the phonTools (
Barreda 2015) and soundgen (
Anikin 2019) packages in R to calculate the approximate VTL from these excerpts (for details, see
Web Appendix A). Consistent with the bioinformational dimensions theory, the estimated VTL, even from a brief sound excerpt, is indeed shorter for Kevin Hart than Dwayne Johnson (VTL
Hart = 15.60 cm; VTL
Johnson = 16.81 cm; corresponding to a predicted body height of 1.75 m vs. 2.00 m, respectively).
Sound Symbolism and Product Congruency
Prior research on sound symbolism revealed that names including frontal (vs. back) vowels and fricative (vs. stop) consonants are more congruent with brands representing smaller, lighter, and more feminine products (
Klink 2000). Similarly, product and brand names including the “i” sound are congruent with smallness (“mil” is more congruent with a small table, whereas “mal” is more congruent with a large table) (
Sapir 1929) and low prices in budget supermarket chains (
Spence 2012). In short, sounds that are congruent with consumers’ expectations positively influence brand and product evaluations (
Lowrey and Shrum 2007).
In related research that used professional human speakers in a radio advertising setting,
Rodero, Larrea, and Vazquez (2013) revealed that a Spanish student population expressed a preference for male (female) voices to advertise stereotypically masculine (feminine) product types (hair removal vs. mechanical products). Such insights are important and highlight the potential for matching effects by utilizing different human voices to advertise products in nonconsumptive, unrelated product domains. However, it still remains unclear to which extent the same voice can be shifted by altering a single vocal feature (i.e., VTL as in the current research), in the same domain, and alter behavioral consumer responses (as opposed to purely perceptual outcomes), across a wide range of samples and study populations (as opposed to a geographically limited setting of a single student population). We expand this prior work and illuminate how AI-generated voices can alter one vocal feature in a single speaker while holding other vocal factors constant, and we explore marketing-related behavioral outcomes for products in two consumptive domains (i.e., food products and cars). This distinctive approach provides novel insights into how the influence of one key vocal feature that can shape physicality attributions (i.e., VTL) may alter consumer behavior in the marketplace.
As VTL shapes the timbre of the human voice and can induce gender-stereotypical attributions regardless of the speaker’s gender (
Ko, Judd, and Blair 2006), we predict that consumers develop an implicit connection of the ideal mapping of the VTL of a speaker and the type of product they envision. This is especially important in the context of artificial speech synthesis with the ability to shift one key feature systematically (e.g., increasing or decreasing the length of the speaker's vocal tract while holding all other vocal features constant), which is impossible in settings where researchers would compare multiple human speakers (e.g.,
Hurtz and Durkin 2004;
Rodero, Larrea, and Vazquez 2013).
Building on this prior work on physicality attributions and differences in VTL, we therefore predict that increasing (decreasing) the VTL of a conversational agent induces perceptions of enhanced (reduced) physicality. We in turn expect that these differences in physicality attributions lead to attributions of enhanced masculinity (femininity) and an enhanced mapping to stereotypically masculine (feminine) products.
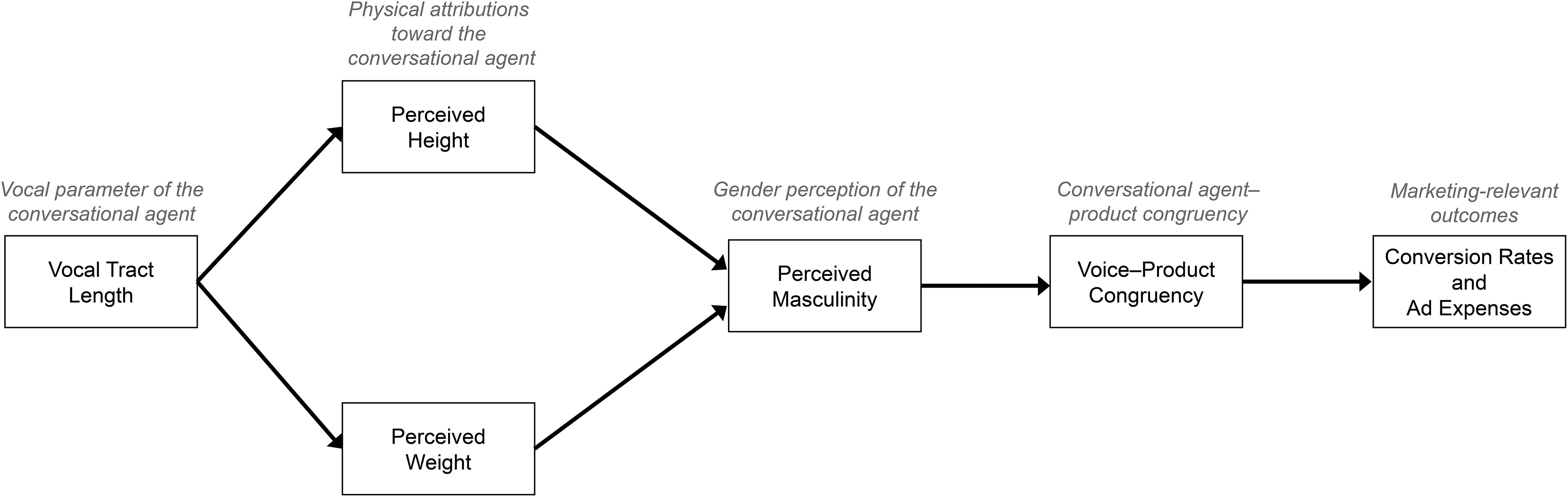
Figure 1 summarizes our conceptual model.
Overview of Studies and Speech-Synthesis Paradigm
We report a series of four studies that test our conceptual model. Study 1 demonstrates that enhancing the digital VTL makes a conversational agent appear heavier and taller. Study 2 replicates these findings and further demonstrates that a longer (shorter) VTL is perceived as more masculine (feminine) and in turn enhances congruency perceptions with stereotypically masculine (feminine) food products (e.g., a beef burger with longer VTL vs. a vegan burger with shorter VTL). Study 3 generalizes these findings to other product domains (i.e., cars) and provides causal evidence that the observed effects are driven by enhancing the VTL, no other, related vocal features, such as pitch or loudness. Study 4 provides large-scale field evidence and demonstrates that such enhanced congruency boosts click-through rates and reduces the cost per impression in advertising settings.
We systematically manipulated the VTL feature of a male voice from Amazon Polly text-to-speech interface (Amazon 2020) using the Speech Synthesis Markup Language (SSML). SSML provides an interface to directly manipulate the VTL using the vocal-tract-length tag (
Dautricourt 2017). For example, reducing the VTL of a conversational agent by 20% for the greeting “Hi” using Amazon Polly would be coded as <amazon:effect vocal-tract-length = “−20%”> Hi </amazon:effect> (for implementation details, see
Web Appendix A). This systematic reduction of the VTL leads to systematic changes of the formant frequencies, which determine the perceived vocal timbre (
Puts, Gaulin, and Verdolini 2006), while controlling for pitch and other vocal features (
Dautricourt 2017). From a technical perspective, changes in VTL alter frequency peaks in the spectrum (
Abhang, Gawali, and Mehrotra 2016) and thus the average spectral envelope of one's speech (
Mackersie, Dewey, and Guthrie 2011). For example,
Figure 2 shows the spectrogram (i.e., representation of the frequency range and loudness of a soundwave over time) of issuing the greeting “Hi” with −20%, baseline, or +20% shifts from the baseline. As illustrated, the frequency range is systematically changing as a function of the VTL manipulation while other features (e.g., pitch, duration, loudness) remain constant.
Study 1
Study 1 examines the key hypothesis: whether changes in digital VTL systematically alter how consumers perceive the physicality of the conversational agent.
Method
Participants and design
We recruited 335 participants from Amazon Mechanical Turk to participate in Study 1. The study was advertised exclusively to participants with sound-capable devices. To ensure that only eligible individuals participated, we included a hardware check (see
Web Appendix A) and excluded 55 participants for failing the attention check. The final sample size for Study 1 was 280 (M
age = 38.12 years; 57% male, 43% female). We used a between-subjects design and randomly assigned participants to one of five conditions that differed in the VTL of a single conversational agent (for details, see the “Experimental Conditions” subsection). We held the content, syntax, and other vocal features constant across conditions. Participants completed an auditory perception task followed by posttask measurements.
Auditory perception task
Participants listened to five randomly generated sentences to mitigate any influence of the semantic content (see
Web Appendix A). Each sentence was presented in random sequence to counter order effects.
Experimental conditions
We used a “male” voice from Amazon Polly as the default voice of the conversational agent across all experiments. The VTL of the baseline conversational agent is measured to be approximately 16.07 cm (see
Web Appendix A), which falls within the range of an average adult man (
Story et al. 2018). We increased and decreased the VTL systematically by 10% intervals using custom SSML code (see the “Overview of Studies and Speech-Synthesis Paradigm” section) to create two long VTL conditions (+10%, +20%) and two short VTL conditions (−10%, −20%), respectively. These percentage differences correspond to an objective change in the speakers formant frequencies from f1 = 519.36 Hz, f2 = 2,004.62 Hz, f3 = 2,547.15 Hz of the baseline voice to f1 = 658.45 Hz, f2 = 2,535.79 Hz, f3 = 3,251.83 Hz (−20% VTL), f1 = 560.64 Hz, f2 = 2,214.45 Hz, f3 = 2,800.76 Hz (−10% VTL), f1 = 455.24 Hz, f2 = 1,815.39 Hz, f3 = 2,329.71 Hz (+10% VTL), and f1 = 413.85 Hz, f2 = 1,684.22 Hz, f3 = 2,184.99 Hz (+20% VTL), respectively. Even though a manipulation in VTL causes significant changes in the formant frequencies (as shown previously), the fundamental frequency (f0) (i.e., the pitch of the voice) remains unaffected. Specifically, analyzing pitch differences between speakers with a computational linguistics software called Praat (
Boersma and Weenink 2021) revealed a nonsignificant difference of less than .5 Hz between conditions, highlighting that the fundamental frequency (i.e., pitch) remained constant between conditions (f0
baseline = 100.02 Hz, f0
−20% = 100.43 Hz, f0
−10% = 100.24 Hz, f0
+10% = 100.26 Hz, f0
+20% = 100.47 Hz). Thus, any differences observed between conditions cannot be attributed to differences in pitch.
Posttask measurements
Inspired by prior work (
Cohen et al. 2015;
Lombardo et al. 2014), participants assessed the conversational agent’s physicality using a 14-point slider scale with visual representations of the perceived height and weight and the conversational agent’s perceived masculinity as a continuum (more feminine to more masculine) using a seven-point Likert scale (see
Web Appendix A).
Results
To compare the means across the five conditions in terms of the perceived weight and height, we first conducted a one-way analysis of variance (ANOVA), followed by planned contrasts (
Kirk 1995).
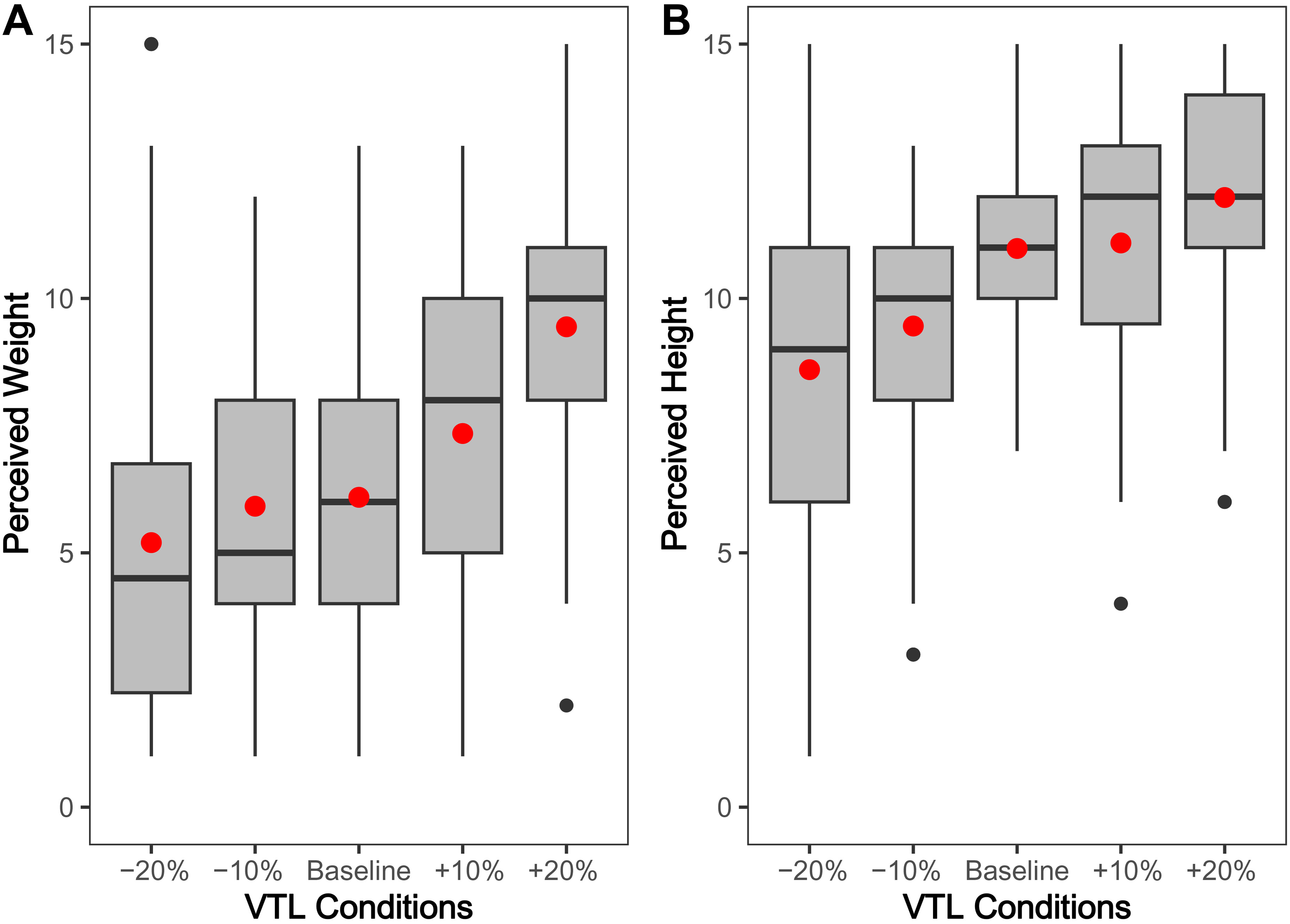
Perceived weight of the conversational agent
A one-way ANOVA revealed significant differences between conditions comparing the perceived weight of the conversational agent (
Figure 3, Panel A; F(4, 275) = 18.67,
p < .001). Follow-up planned contrasts revealed that both +10% (M
+10% = 7.34, SD
+10% = 2.95; t(275) = 2.24,
p < .05) and +20% (M
+20% = 7.34, SD
+20% = 2.95; t(275) = 6.14,
p < .001) agents were perceived as significantly heavier than the baseline (M
baseline = 6.09, SD
baseline = 2.62; the remaining comparisons with baseline were non-significant with all
ps > .05). There was no significant interaction effect observed between participant gender and the perceived weight of the conversational agent (
p = .51).
Perceived height of the conversational agent
As expected, differences in VTL also led to altered perceptions of height (
Figure 3, Panel B). A one-way ANOVA revealed a significant effect of VTL on perceived height (F(4, 275) = 14.77,
p < .001). Specifically, planned contrasts revealed that the +20% agent was perceived as significantly taller (M
+20% = 11.98, SD
+20% = 2.31; t(275) = 2.04,
p < .05), and both −10% (M
−10% = 9.45, SD
−10% = 2.24; t(275) = −3.08,
p < .01) and −20% (M
−20% = 8.60, SD
−20% = 3.95; t(275) = −4.62,
p < .001) were perceived as significantly shorter than baseline (M
baseline = 10.98, SD
baseline = 2.01). Again, we found no interaction between participant gender and perceived height of the conversational agent (
p = .14).
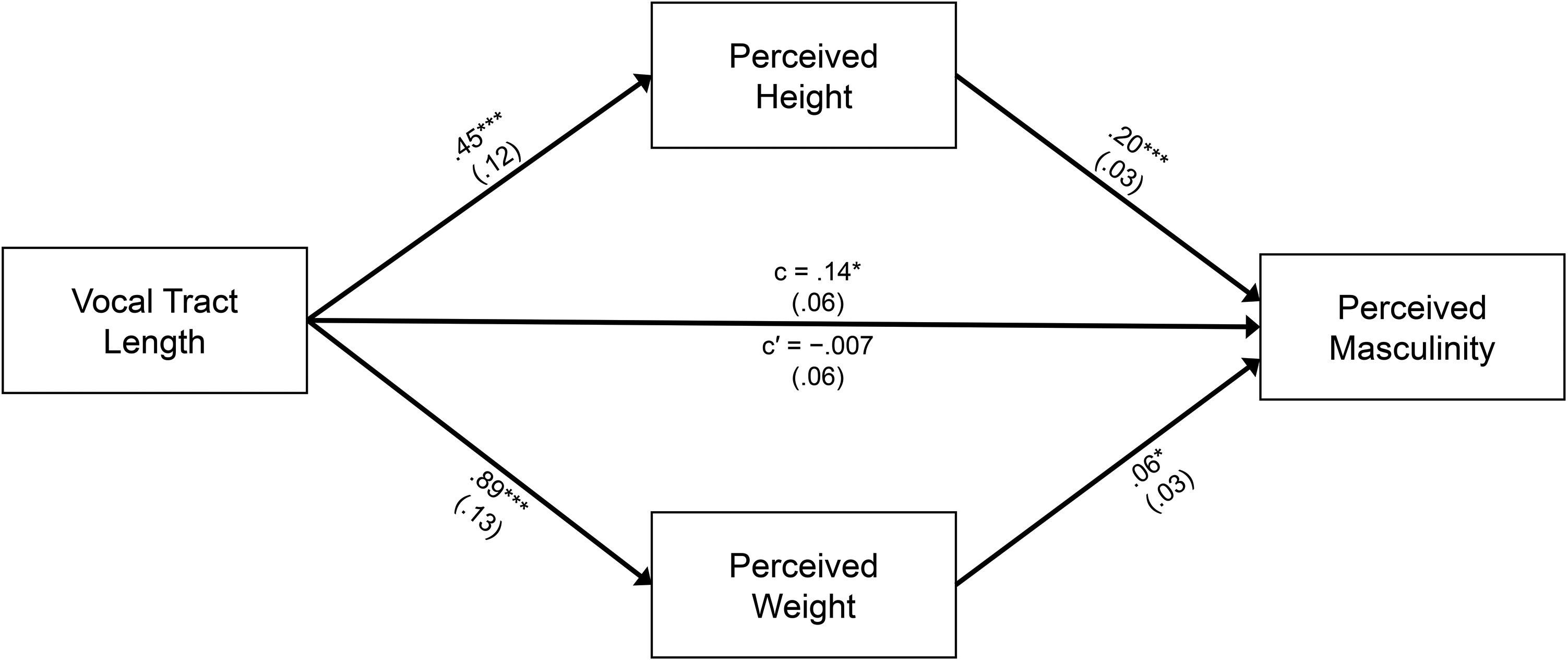
Next, we examined whether the perceived height and weight of the conversational agent mediated the relationship between VTL and the conversational agent's perceived masculinity. We performed a parallel mediation analysis with two mediators (height and weight; Model 4 with 5,000 bootstrap resamples [
Hayes 2017]). This model included the VTL conditions as the independent variable, perceived height and weight as parallel mediators, and perceived level of masculinity as the dependent variable.
As predicted, we found a significant total effect of the −20% agent (b = −1.06, 95% CI: [−1.60, −.54]) and the −10% agent (b = −1.01, 95% CI: [−1.52, −.50]) on the perceived level of masculinity. Additionally, we found a significant direct effect of VTL on the perceived level of masculinity for both the −20% (b = −.62, 95% CI: [−1.14, −.10]) and the −10% (b = −.74, 95% CI: [−1.23, −.25]) agents. Finally, we observed a significant indirect effect of the perceived height on the perceived level of masculinity (b = .17, 95% CI: [.11, .23]).
In summary, increasing the VTL of the conversational agent led participants to perceive the agent as heavier and taller, which subsequently enhanced perceptions of masculinity (
Figure 4).
Discussion
Study 1 provides evidence for our key hypothesis that people use VTL as a proxy to infer physical traits of conversational agents. Our results further illustrate that enhanced physicality attributions in turn enhances perceptions of masculinity.
Study 2
The key objective of Study 2 was to further examine whether differences in VTL impact not only physicality attributions but also downstream voice–product congruency perceptions of consumers.
Method
Participants and design
We recruited 464 participants on Amazon Mechanical Turk and excluded 98 participants for failing the same attention check as in Study 1. Thus, a final sample of 366 participants (Mage = 36.24 years; 59% male, 41% female) were randomly assigned to a short (−20%), long (+20%), or baseline VTL condition. All participants completed the same hardware precheck as in Study 1, and we used the same text-to-speech interface to alter the VTL of the conversational agent, holding all other vocal features constant (e.g., pitch, loudness, speech rate). Participants completed the same scales to assess the perceived physicality and perceived level of masculinity as in Study 1.
Product congruency task
Inspired by prior work on gender-based food stereotypes (
Ekebas-Turedi et al. 2021;
Gough 2007;
Lyons 2009;
Zhu et al. 2015), we used a binary food choice task. Specifically, we showed participants six randomized binary food options: one stereotypically feminine option (e.g., vegan burger, low-calorie yogurt) and one stereotypically masculine option (e.g., beef burger, nachos with cheddar cheese) (for all stimuli, see
Web Appendix A). We then asked participants to select the product that fits best with the voice of the conversational agent they interacted with previously. Next, we created a “product masculinity index” by coding masculine product choices as 1 and feminine product choices as 0, then summing the scores of the six pairs of products.
Results
Perceived weight of the conversational agent
Replicating the findings of Study 1, a one-way ANOVA showed that the VTL systematically influenced perceptions of weight (F(2, 363) = 27.47, p < .001). Follow-up planned contrasts confirmed that the +20% agent was perceived as significantly heavier than the baseline agent (M+20% = 8.65, SD+20% = 3.02; Mbaseline = 6.24, SDbaseline = 2.66; t(363) = 6.19, p < .001).
Perceived height of the conversational agent
Replicating the findings of Study 1, we also found a significant effect of VTL on perceived height (F(2, 363) = 26.55, p < .001), with the −20% agent perceived as significantly shorter than the baseline voice (M−20% = 8.71, SD−20% = 3.33; Mbaseline = 10.92, SDbaseline = 2.42; t(363) = −6.16, p < .001).
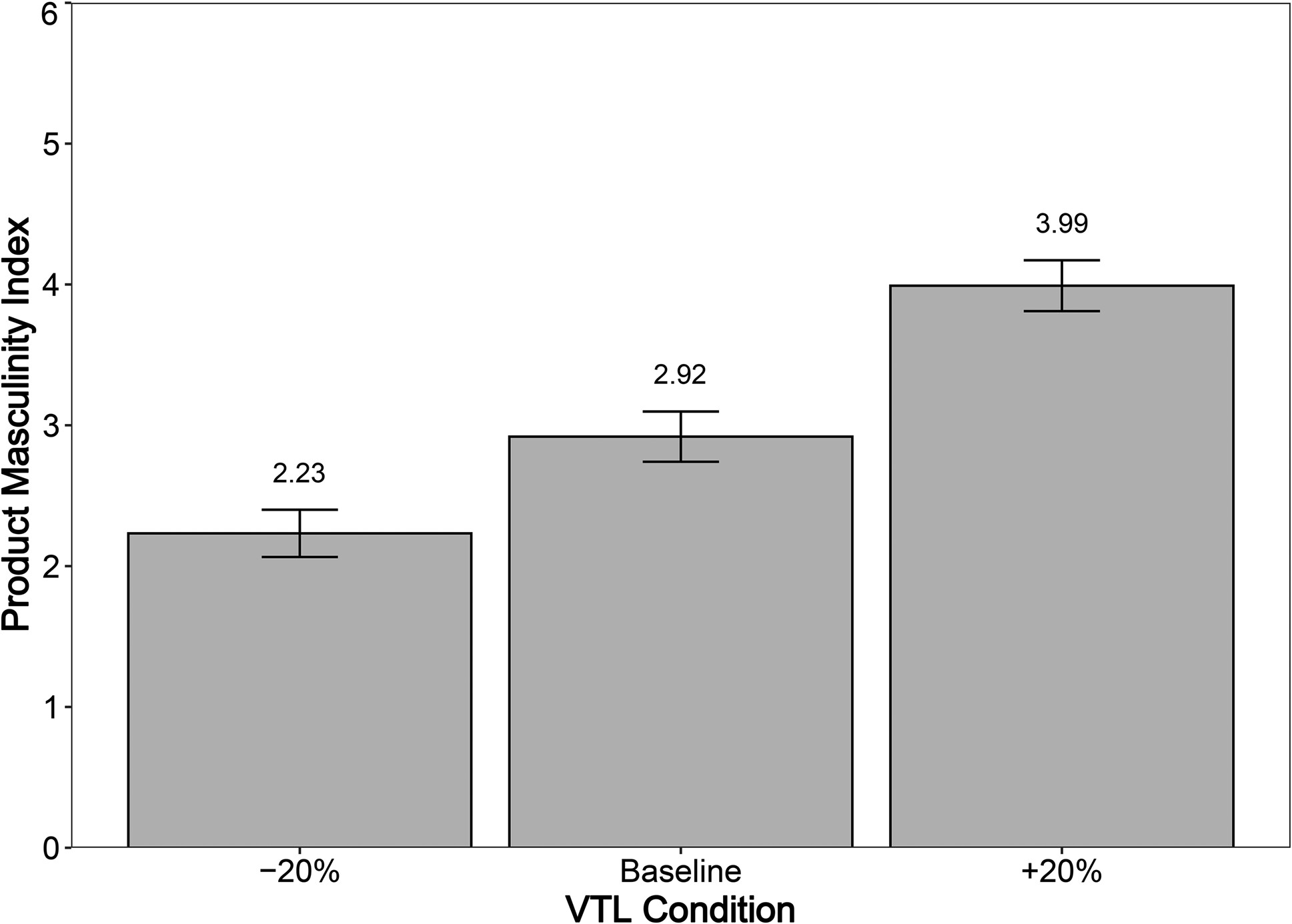
In line with our predictions and as shown in
Figure 5, VTL significantly impacted perceived congruency (F(2, 363) = 25,
p < .001). The +20% agent was perceived as a significantly better fit for masculine food products than the baseline agent (M
+20% = 3.99, SD
+20% = 1.92; M
baseline = 2.92, SD
baseline = 1.99; t(363) = 4.25,
p < .001), indicating greater congruency between the long VTL agent and stereotypically masculine food products. Similarly, the −20% agent was perceived as a significantly better fit for feminine food products than the baseline voice (M
−20% = 2.23, SD
−20% = 1.91; t(363) = −2.82,
p < .01), suggesting greater congruency between the short VTL agent and stereotypically feminine food products.
Next, we examined the mediating role of the conversational agent's perceived height and weight on the perceived level of masculinity and in turn on voice–food product congruency. We performed a serial mediation model with three mediators (Model 80 with 5,000 bootstrap resamples [
Hayes 2017]), entering VTL as the independent variable, perceived height and weight as the proximal mediators, perceived masculinity as the distal mediator, and voice–product congruency as the dependent variable.
The results demonstrate a significant total effect of VTL on perceived voice–food product congruency (b = .52, 95% CI: [.26, .77]). The effect of VTL on congruency was significantly mediated by consumers’ attribution of height (b = .12, 95% CI: [.05, .19]) and the subsequent impact of enhanced masculinity on congruency perceptions (b = .25, 95% CI: [.11, .39]), with an indirect effect excluding zero (contrasting the −20% agent; bindirect = −.06, 95% CI: [−.13, −.01]).
Discussion
Study 2 demonstrates greater congruency perceptions between a long (short) VTL conversational agent and gendered food products. In line with our theorizing, we further show that these changes can be explained by differences in the perceived physicality of the conversational agent. While the first two studies demonstrate that increasing the VTL of a conversational agent indeed shapes attributions of physicality (i.e., taller and heavier) and in turn shapes product congruency, we cannot formally rule out the potential impact of other vocal features. For example, even though we isolated the effect of VTL while holding all other features constant, it is conceivable that merely altering the fundamental frequency (i.e., pitch) or loudness of a speaker is sufficient to promote similar levels of physicality attributions. The next study tests this possibility.
Study 3
The objective of Study 3 was twofold: Testing whether the current effects (1) can be explained by other, related vocal features and (2) are robust across product domains. To address the first point, the current study investigates whether the impact of VTL on perceived physicality, masculinity, and voice–product congruency is unique compared with other vocal features, such as pitch and loudness. Second, the current study examines the predicted effects in a setting in which we entirely remove the possibility that the previous results might have been driven by potential eating–weight effects that could have strengthened the previous results. The current study therefore tests our theorizing in a nonfood setting (i.e., cars).
Method
Participants and design
We recruited a sample of 600 participants from Prolific, and we excluded 26 participants for failing an attention check. The final sample consisted of 574 participants (M
age = 38.77 years; 49% male, 51% female) who were randomly assigned to one of six conditions in a between-subjects design. These six conditions contrast an increased VTL against five key contrasts that could pose a threat to the current findings (i.e., that the current findings are merely a function of reducing the pitch of a speaker or speaking with enhanced loudness to promote masculinity attributions and in turn product congruency). It is also conceivable that VTL interacts with these related vocal features. We therefore randomly assigned participants to one of six vocal manipulations: (1) enhanced vocal tract (+20%), (2) decreased pitch (−20%), (3) increased loudness (+4 dB), (4) enhanced vocal tract (+20%) with decreased pitch (−20%), (5) enhanced vocal tract (+20%) with increased loudness (+4 dB), or (6) the default voice (baseline). The loudness enhancement was inspired by prior work on acoustics and the finding that a 4 dB increase represents a perceptually noticeable difference in terms of loudness (
Allen, Hall, and Jeng 1990;
Warren 1973). As in the previous studies, we used SSML in Amazon Polly to alter all vocal features.
Before the experiment, and identical to the previous studies, participants completed a hardware precheck and an auditory perception task. Following this task, participants assessed the perceived physicality and level of masculinity of the conversational agent using the same scales as in the previous studies. After repeating the auditory perception task to refresh their memory, participants completed a binary choice task to evaluate the congruency between the product domain (i.e., cars) and the conversational agent's voice.
Product congruency task
Mirroring the paradigm used in Study 2, we presented participants with six randomized binary car product options: one stereotypically feminine option (e.g., Fiat 500, Smart EQ) and one stereotypically masculine option (e.g., BMW M3, Chevrolet Camaro) (for details, see
Web Appendix A). We selected these cars after pretesting ten stereotypically feminine cars and ten stereotypically masculine cars based on their characteristics—such as color, size, and extent of edges—which are known to influence the perceived femininity versus masculinity of a product (
Alreck 1994;
Franck and Rosen 1949;
Van Tilburg et al. 2015). From these pretested cars, we selected the six most feminine cars and the six most masculine cars then created six random pairs, ensuring the same number of comparisons as in Study 2. Participants were instructed to choose the product that best matched the voice of the conversational agent they previously interacted with. As in the previous study, we created a product masculinity index by coding masculine product choices as 1 and feminine product choices as 0 then summing the scores of the six pairs of products (for all the stimuli and details of the pretest, see
Web Appendix A).
Results
Perceived weight of the conversational agent across vocal manipulations
A one-way ANOVA revealed significant differences in the perceived weight across the different vocal manipulations (F(5, 568) = 44.10, p < .001). Follow-up planned contrasts showed that enhancing the vocal tract of the conversational agent led to significantly increased perceptions of weight compared with all other vocal manipulations (MVTL = 9.78, SDVTL = 2.69; Mbaseline = 5.67, SDbaseline = 2.48; t(568) = 10.51, p < .001; Mpitch = 6.08, SDpitch = 2.41; t(568) = 9.61, p < .001; Mloudness = 6.09, SDloudness = 2.75; t(568) = 9.55, p < .001; MVTLpitch = 8.99, SDVTLpitch = 2.81; t(568) = 2.01, p < .05; MVTLloudness = 8.92, SDVTlLoudnes = 2.99; t(568) = 2.18, p < .05). By contrast, manipulating pitch or loudness did not significantly influence the perceived weight of the conversational agent (p > .05). Most importantly, we also found that adding more loudness or reducing the pitch of the speaker along with increasing the VTL led to nonsignificant differences compared with the systematic increase in VTL alone.
Perceived height of the conversational agent across vocal manipulations
A one-way ANOVA revealed significant differences between the different vocal manipulations on perceived height (F(5, 568) = 5.94, p < .001). Planned contrasts further revealed that enhancing the vocal tract of the conversational agent led to increased perceptions of height compared with the baseline (MVTL = 11.89, SDVTL = 2.19, Mbaseline = 11.18, SDbaseline = 2.00; t(568) = 2.25, p < .05), pitch (Mpitch = 10.85, SDpitch = 2.05; t(568) = 3.34, p < .001), as well as loudness (Mloudness = 10.80, SDloudness = 2.17; t(568) = 3.50, p < .001). Similar to weight perceptions, no differences in the perceived height of the conversational agent were found between baseline, pitch, and loudness conditions (p > .05). As with weight, further decreasing the pitch or increasing the loudness while increasing the vocal tract of the conversational agent did not influence the perceptions of height more than when only increasing the vocal tract (p > .05).
Perceived masculinity of the conversational agent across vocal manipulations
A one-way ANOVA revealed significant differences between the different vocal manipulations (F(5, 568) = 4.19, p < .001). Planned contrasts showed that increasing the vocal tract of the conversational agent led to enhanced perceptions of product masculinity compared with the baseline (MVTL = 6.05, SDVTL = .99; Mbaseline = 5.60, SDbaseline = 1.25; t(568) = 2.92, p < .01), pitch (Mpitch = 5.68, SDpitch = 1.04; t(568) = 2.48, p < .05), and loudness (Mloudness = 5.73, SDloudness = 1.05; t(568) = 2.16, p < .05). No differences in the perceived masculinity of the conversational agent were found between baseline, pitch, and loudness conditions (p > .05). As previously, the increase in the perceived masculinity of the conversational agent due to VTL manipulation does not appear to be further amplified when the pitch is decreased or the loudness is increased (p > .05).
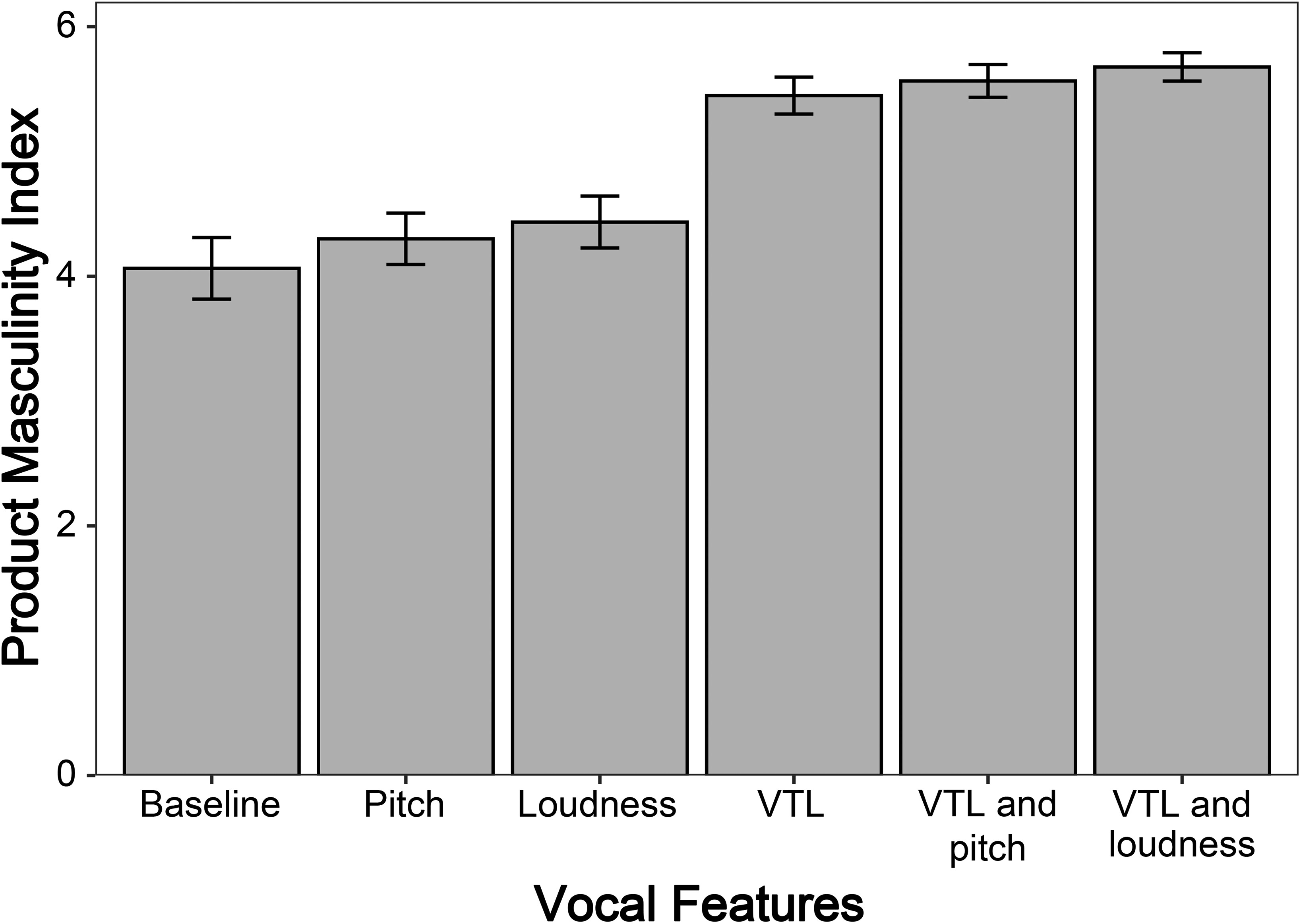
Perceived voice–product congruency across vocal manipulations
Finally, we also examined the perceived voice–product congruency across the vocal manipulations using a different product category than in Study 2 (cars instead of food products). Extending the previous findings, a one-way ANOVA revealed significant differences between the different vocal manipulations (F(5, 568) = 15.49,
p < .001). The follow-up contrasts revealed that the VTL condition was rated significantly higher in perceived voice–product congruency with masculine cars compared with the baseline (M
VTL = 5.45, SD
VTL = 1.45; M
baseline = 4.06, SD
baseline = 2.39; t(568) = 5.32,
p < .001), pitch (M
pitch = 4.30, SD
pitch = 2.06; t(568) = 4.48,
p < .001), and loudness (M
loudness = 4.43, SD
loudness = 2.07; t(568) = 3.95,
p < .001; see
Figure 6). As previously, there was no significant difference in perceived voice–product congruency between manipulating only VTL and combining it with pitch or loudness (all
ps > .05).
Discussion
Study 3 demonstrates that the current findings are not driven by other, related vocal features (e.g., reduced pitch or enhanced loudness, which could also impact enhanced physical attributions and product masculinity perceptions). In fact, the current findings are indeed specific to variations in VTL and generalize across product domains (cars in Study 3 compared with food in Study 2). One key question that remains is whether the current effects also have more directly measurable economic implications. The next study provides a large-scale test on whether changes in VTL lead to objective changes in downstream advertising effectiveness.
Study 4
Given the recent shift of employing artificially generated voices in advertising settings (
Campbell et al. 2022;
Mari 2019;
Pajupuu et al. 2023), the current study explicitly examined the impact of changes in VTL on downstream ad performance. Specifically, Study 4 takes the form of a large-scale field experiment to test the downstream economic consequences of enhanced voice–product congruency on click-through rates and costs in an online advertising setting.
Method
Participants and design
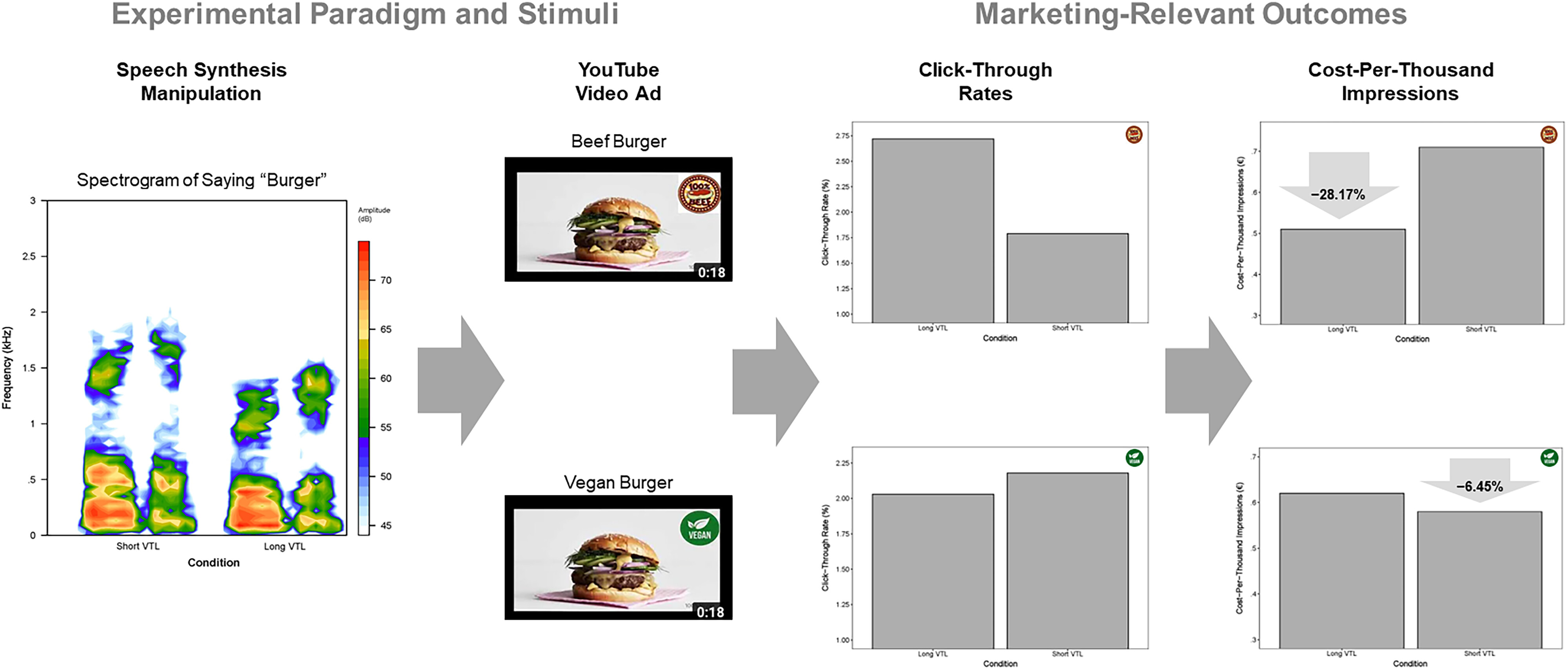
The field experiment employed a 2 (VTL shifts: long [+20%] vs. short [−20%] VTL) × 2 (food products: masculine [beef burger] vs. feminine [vegan burger]) between-subjects design. We created four distinct ad campaigns that we ran simultaneously for three days on YouTube's advertising platform (Google Ads), targeting exclusively English-speaking users. We selected a skippable in-stream video ad with a cost-per-impression bidding strategy. A total of 35,430 consumers were exposed to the advertisement. The demographics across all campaigns were very similar: approximately 50% of the viewers were between 18–34 years old, 65% of viewers were male, and 35% of viewers were female.
Stimuli and procedure
We created an 18-second video depicting a static image of a burger with a voiceover of the conversational agent promoting a fictional burger brand. The linguistic content of the message was identical except for replacing the word “beef” with “vegan” in two conditions. Each message was communicated by either the −20% VTL or the +20% VTL agent used in the preceding studies. Viewers who clicked on the provided URL were redirected to an external landing page for our fictional burger brand, were debriefed, and had the chance to leave their email address if they had questions about the study (see
Web Appendix A). The main dependent variables were users’ click-through rate (i.e., number of ad clickers divided by number of viewers) and the cost per impression as calculated by the Google Ads platform.
Results
In support of our theorizing, a two-proportions z-test revealed that the beef burger advertisement led to significantly greater click-through rates when promoted by the longer VTL agent (260 out of 9,560; 2.72%) than the shorter VTL agent (160 out of 8,940; 1.79%) (χ2(1) = 17.59, p < .001). In the vegan burger advertisements, the shorter VTL agent led to directionally greater click-through rates (188 out of 8,640; 2.18%) than the longer VTL agent (169 out of 8,290; 2.03%), although this difference did not reach significance (p = .28).
To further demonstrate the economic implications of these effects, we calculated the differences in costs at the within-product level. We found that employing a congruent (vs. incongruent) conversational agent in the beef burger advertisement reduced advertising costs by 28.17% (from €.71 to €.51 per 1,000 impressions) and in the vegan burger advertisement by 6.45% (from €.62 to €.58 per 1,000 impressions) (for a summary of the field study results, see
Figure 7).
Discussion
The current field experiment demonstrates in a highly ecologically valid setting that changing the VTL of a conversational agent systematically impacts downstream advertising performance (higher click-through rates and lower costs). We provide evidence that an enhanced VTL boosts perceptions of product congruency that in turn leads to improved advertising performance.
General Discussion
Our findings make three novel contributions. They provide a new look at congruency effects in marketing, illuminate the unexplored potential of artificial speech synthesis as a novel method in marketing, and highlight important design implications for the future of voice marketing for firms.
First, we provide a theory-driven design of conversational agents building on prior “matching leads to greater persuasion” effects (
De Bellis et al. 2019). The current work demonstrates that matching the vocal features of a conversational agent with the advertised product causes an increase in consumers’ subjective evaluation and objective changes in behavior (e.g., online click-through rates; Study 4). While human employees can only minimally adjust their vocal characteristics (
Titze 2008;
Zhang 2016), developing conversational agents at scale to advertise different types of products by altering their vocal features provides the opportunity for a more consistent mapping and design of vocal characteristics to shape consumers’ perception of a product or brand.
Second, the current work introduces computational speech synthesis models as an unexplored method in marketing; more specifically, it introduces the integration of computational speech synthesis with sound symbolism research (for a review, see
Hildebrand et al. [2020] and
Krishna [2012]). As shown in this research, SSML provides a versatile interface (or language) to design vocal stimuli for a broad range of marketing-relevant phenomena, such as mapping voice characteristics to products (as in the current research) and the future design of a vocal brand personality. To the best of our knowledge, this is the first line of research at the intersection of speech synthesis, sound symbolism, and interactive sensory marketing, showing that the theory-driven design of artificial voices creates unique mental representations for consumers (in the current research, the physical attributions associated with the sound of the voice mapped onto a unique set of products).
Finally, the current research also has important design implications for the future of AI-powered conversational agents in voice marketing. This research indicates the potential risk of a one-size-fits-all strategy for developing AI-powered conversational agents (
Hildebrand, Hoffman, and Novak 2021). We demonstrate that such agents can be specifically designed, or engineered, to map the target product’s gender with longer (vs. shorter) VTL. Contributing to the emerging field of voice marketing (
Hildebrand et al. 2020;
Hildebrand, Hoffman, and Novak 2021;
Melumad 2023;
Zierau et al. 2022), our results demonstrate that enhanced voice–product congruency leads to substantially more effective advertising performance and overall economic benefits such as reduced cost per impression (Study 4). Companies are advised to think more systematically about the vocal design of AI-powered conversational agents as opposed to using off-the-shelf alternatives. The customizability of Amazon Polly and other text-to-speech APIs enables firms across industries to design their preferred “voice product profile” for the advertised product and the brand. From a broader market perspective, these developments can potentially replace the dominant advertising model of using human actors as opposed to more intentionally designed conversational agents that could provide faster, cheaper, and arguably more firm-consistent communication between consumers and firms.
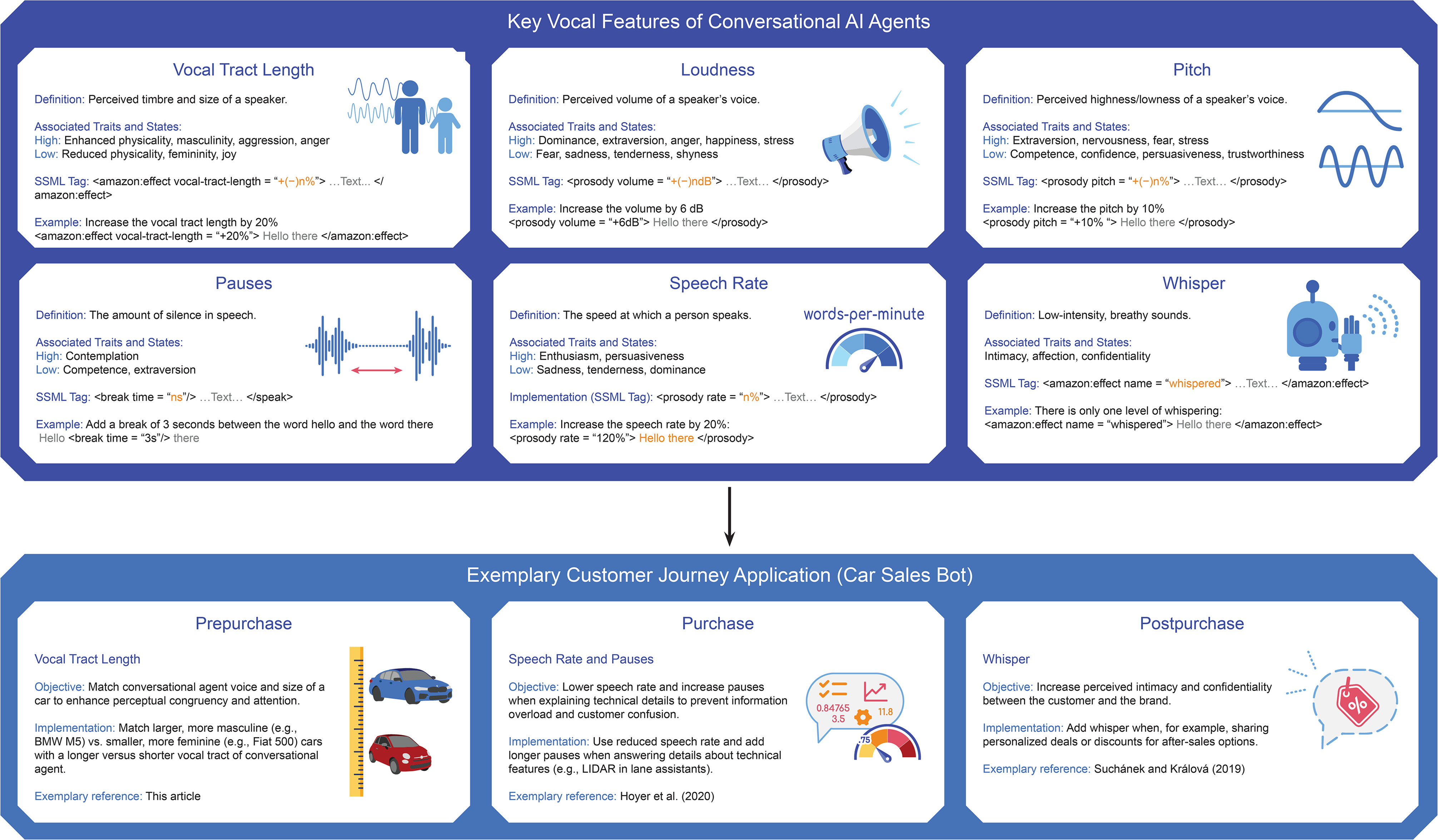
The current work also introduces computational speech synthesis as an unexplored “toolbox” in voice marketing efforts. For example, marketers may intentionally design or engineer specific voice profiles along unique stages of a typical customer journey.
Figure 8 highlights some of the key vocal features in marketers' voice marketing toolbox (VTL, pitch, loudness, speech rate, pauses, and whisper) and how they can be combined to achieve a given marketing objective. For instance, at the beginning of a customer journey (prepurchase stage), firms may try to boost the match of their advertised product and the VTL of the conversational agent to leverage attention and ease of processing. As soon as consumers transition to the actual purchase phase, a greater range of technical and more implementation-oriented questions are discussed (
Barwitz and Maas 2018;
Hoyer et al. 2020). As this phase is often characterized by enhanced complexity, reducing the speech rate of the conversational agent would be a simple way to ease processing for consumers. Finally, when consumers transition into the postpurchase phase, brands need to establish (and renew) the commitment to the customer relationship. Building on prior work in human-to-human conversation, using a whispering tone during a conversation with close others creates a sense of intimacy that could lead to enhanced levels of trust and a more communal (as opposed to instrumental) perception of the relationship (
Andersen 2015;
Hartmann, Bergner, and Hildebrand 2023); thus, brands could employ a whispering feature to create a more intimate relationship with consumers in the postpurchase phase.
In summary, the vocal features in our toolbox can be combined in the future design of conversational agents’ voices, further opening the space for marketers and designers to build unique and tailored voices that meet specific marketing and branding needs. We hope that this toolbox view of computational speech synthesis opens up new avenues for future voice marketing efforts and offers a starting point for firms seeking to leverage the power of AI-generated voices in their marketing and branding campaigns.
Future Research
While our research has focused on the systematic manipulation of a single vocal feature (i.e., VTL), we highlight two important avenues for future research. First, future work could further explore cross-modal effects between the vocal features of AI-powered conversational agents and other characteristics, such as their visual appearance. This multisensory line of research is particularly important given the rise of AI-powered technologies that combine multiple modalities, such as the voice and look of an AI-generated avatar. Second, while the current work focused on the congruency of voice and product features, future work could expand to illuminate brand–voice congruency effects. The current work may also offer new directions to explore either related constructs that could be mapped onto vocal features of a conversational agent, such as pitch and VTL for “brand gender” perceptions (
Pernet and Belin 2012), or how vocal features shape attributions of more subtle and less observable attributes, such as matching the ideal voice to an envisioned “brand personality.” We hope that this article stimulates more research on the effective design of AI-generated voices at the intersection of marketing, psychology, and human–computer interaction, as well as more work on how firms can make more theory-driven decisions to optimize their voice marketing strategy moving forward.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.