4.1 Regression-based examples and performance
We begin by presenting a particularly simple case. Consider the following linear model, in which 10 outcome variables ys are regressed on a single independent variable, treat. Superscript-s terms refer to each of the multiple outcomes, of which there are a total of S, or their determinants. The data-generating process (DGP) is simulated as
for observation i. For each observation i, the 10 stochastic error terms are drawn from a multivariate normal (mvn) distribution, following
with ρ ≥ 0, and the independent variable of interest, treat i, is generated as treat i , where 1 denotes the indicator function and Ui ∼ U(0, 1). This is a highly stylized setting, but it allows us to vary the correlation between the multiple outcome variables of interest (y 1 , y 2 ,…, y 10) via the parameter ρ, as well as the impact of treatment via the parameter . In particular, we can examine both the empirical fwer and the empirical proportion of false null hypotheses that get rejected (that is, power). We can examine this performance not only for the Romano–Wolf procedure but also for Holm’s procedure and for naïve procedures that do not account for multiple testing.
We consider a series of simulations based on N = 100 observations. Each null hypothesis is that , versus the two-sided alternative hypothesis . Across simulations, we vary the number of models in k = 1, 2,…, 10 for which , as well as ρ, the correlation between outcomes induced by the stochastic error terms. Below, we document one such simulation and resulting multiple-hypothesis correction.
In the simulation below, each of the 10
terms is equal to 0, and the correlation between draws in the
mvn distribution is set at
ρ = 0.25. We follow the
dgp described above, where first we simulate
treat i (as
treat), and then we generate
εi as a draw from an MVN. This draw is generated using a transformation of independent normal draws using a Cholesky decomposition of the desired covariance matrix and Stata’s
matrix score command to multiply row vectors.
12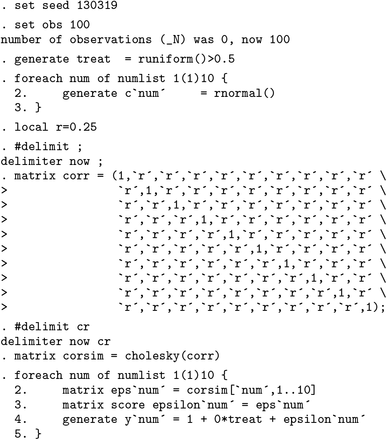

Once we have simulated the
N ×
S matrix
Y in the above code, we apply the Romano–Wolf stepdown correction. Here we are considering the
S = 10 outcome variables
y1–
y10 and the single independent variable
treat. We request that the command perform 1,000 bootstrap repetitions, which, given the lack of other options, will be performed by resampling observational units with replacement. By specifying the
nodots and
holm options, we request that no dots be displayed on the Stata output to indicate the degree to which the resample procedure has advanced, and we request for
rwolf to return
p-values corrected using
Holm’s (1979) procedure (which will be listed in the final column of tabular output and saved in the returned
e() list).
The command returns a list of p-values associated with each of the multiple outcomes. The column Model p-value lists the analytical p-values coming directly from the estimated regression model based, in each case, on the t statistic and the (inverse) cumulative distribution function of a t distribution with appropriate degrees of freedom. The column Resample p-value lists the resampling-based p-values as per (6), which also do not correct for multiple testing. In the case of both of these uncorrected procedures, despite the fact that all true β 1 values were 0, many of the hypotheses that β 1 = 0 are rejected at α = 0.05. In particular, the variables y4 and y7 have p-values below 0.05 for both uncorrected procedures. The third column displays the Romano–Wolf adjusted p-values, where we note that now no null hypothesis is rejected (even at α = 0.10).
The simulated example above provides one example of a multiple-hypothesis correction based upon a known DGP. To examine the performance of the
rwolf command (and the Romano–Wolf correction in this context) more generally, we can examine the error rates and proportion of hypotheses correctly rejected when we vary the number of values of
β 1 s = 0 and the correlation between outcomes,
ρ. We consider such an example in
tables 1 and
2 (which are in the spirit of
tables 1–3 in
Romano and Wolf [2005a]). The first table considers the proportion of times at least one null hypothesis is rejected when the null hypothesis is actually true (the FWER), and the second table considers the proportion of hypotheses that are correctly rejected when the null hypothesis is false (the power of the tests).
13In these tables, we consider 1) a series of models where all of the
β 1 s terms are equal to 0 (presented in panel A of
table 1), 2) a series where half of the
β 1 s terms are equal to 0 and the other half are equal to 0.5 (presented in panel B of
table 1 when considering FWERs and panel A of
table 2 when considering power),
14 and 3) a series where all of the
β 1 s terms are equal to 0.5 (presented in panel B of
table 2). Case 1 is not considered in
table 2 given that all null hypotheses are true and so cannot be “correctly rejected”. Similarly, case 3 is not considered in
table 1 given that all null hypotheses are false and so the FWER is trivially equal to 0 given that they cannot be “incorrectly rejected”. Across columns, we vary the degree of correlation between outcomes, from
ρ = 0 in the first two columns, to
ρ = 0.75 in the final two columns. The nominal levels for the FWER are set at
α = 0.05 and
α = 0.10, respectively.
Here we briefly discuss the performance of the rwolf command and note several important features of the Romano–Wolf multiple-hypothesis correction. In particular, we always present the performance criteria for three testing procedures: those corresponding to the naïve case, where no correction for multiple-hypothesis testing is made; those corresponding to Holm’s procedure; and those corresponding to the Romano–Wolf procedure.
In panel A of
table 1 (where all values for
), it is clear in the uncorrected case that the empirical
FWERs greatly exceed nominal levels of
α = 0.05 and 0.10. When all outcomes are uncorrelated, these values are 0.396 and 0.642, respectively, suggesting a large proportion of families in which a null hypothesis is incorrectly rejected, in line with that predicted in theory.
15 As the correlation between outcomes grows, these naïve values fall closer to the nominal levels but still considerably exceed desired error rates.
With the Holm correction, we observe that the FWER is controlled at both the 5% and 10% levels. This is observed regardless of the degree of correlation considered, between
ρ = 0 and
ρ = 0.75. Similar control is observed with the Romano–Wolf procedure. Indeed, in each case the empirical FWER is very close to the desired nominal rate of 0.05 or 0.10, respectively. In panel B of
table 1 (where 5 of the 10 hypotheses should not be rejected), we again observe that the FWER without multiple-hypothesis correction still substantially exceeds desired error rates but is successfully controlled at no more than
α with both the Holm and Romano–Wolf procedures.
In
table 2, we can examine the relative power of the Holm and Romano–Wolf procedures for rejecting false null hypotheses. In panel A of
table 2, we return to the case considered in panel B of
table 1, here considering the power of the tests instead. In this setting, the naïve case of no multiple-hypothesis correction allows us to reject a large proportion of false null hypotheses (at the cost of the FWER documented in
table 1).
In the case of Holm and Romano–Wolf, we observe relatively similar rates of correct rejection when the correlation between outcomes is 0, but as expected, as the correlation between outcomes grows, the Romano–Wolf procedure substantially improves relative to Holm’s procedure. For example, in the final column of panel A, we reject 59.4% of false null hypotheses using the Romano–Wolf procedure versus only 46.8% using Holm’s procedure, a 27% improvement in rejection rate. A similar pattern is observed in
table 2, panel B (where all null hypotheses are false). Initially, when the correlation between outcomes is 0, Holm’s and Romano–Wolf’s procedures have similar power; however, to the degree that
ρ increases, the Romano–Wolf procedure becomes relatively more powerful.
In
table 2, we consider the relative power of testing procedures for rejecting false null hypotheses with a particular value for
β 1 s, in this case,
for all cases where
. The relative power of these procedures will depend on the actual value of
β 1 s. Below, in
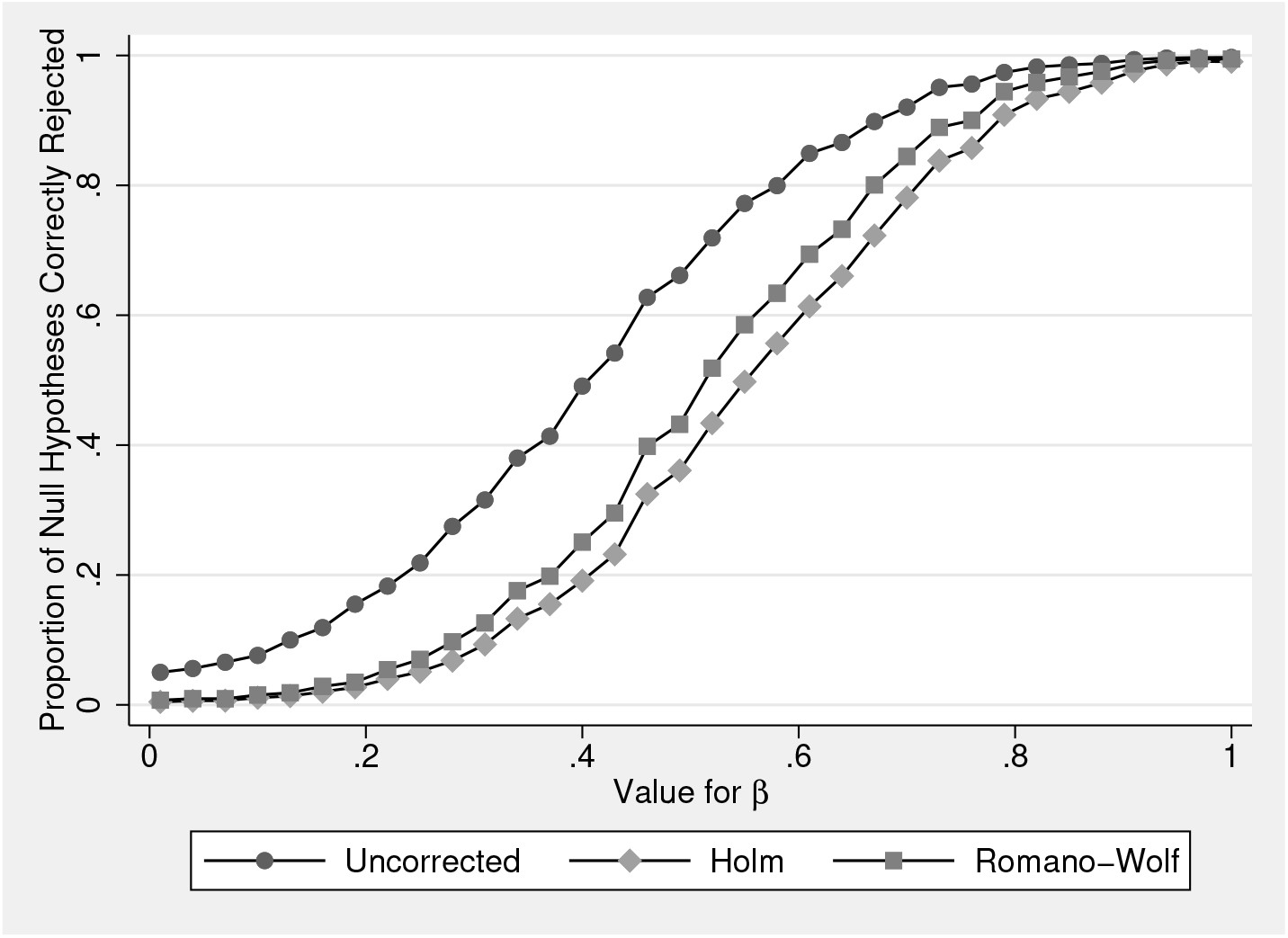
figure 1, we consider how these rates of rejection vary with
values. In the figure, we consider the case corresponding to
table 2 panel B (where all
) and where
ρ = 0.5. We present values of
varying from 0.01 to 1, in steps of 0.03. All other details follow the
DGP in (8).
For each value of β 1, we run 1,000 simulations, in each case calculating the unadjusted p-values, and the Holm and Romano–Wolf p-values using the rwolf command. Across the 1,000 simulations, we examine the proportion of null hypotheses correctly rejected. As expected, the power when not conducting any multiple-hypothesis correction is greatest (at the cost of exceeding the FWER if the null hypothesis were true). To the degree that the correlation between outcomes approaches ρ = 1, the power of the Romano–Wolf procedure will approach the power of the procedure with no multiplehypothesis correction.
Of interest is the relative performance of Romano–Wolf’s versus Holm’s correction. Here, given that ρ = 0.5, the power of the Romano–Wolf correction dominates the power of the Holm correction across each value for β 1. This difference is particularly notable at values of β 1 between 0.4 and 0.6, and all disappear as β 1 becomes large, implying sufficient power to reject all null hypotheses regardless of the correction procedure. When β 1 = 1, each of the procedures results in rejection rates of around 100%.
The simulated examples based on rwolf displayed previously provide a standard implementation where multiple outcome variables are regressed on a single independent (treatment) variable, each using an ordinary least-squares regression. However, the standard command syntax of rwolf allows for many extensions of this baseline implementation. This includes the use of alternative estimation methods (for example, IV regression, probit, and other Stata estimation commands), the implementation of one-sided tests, or the use of alternative bootstrap routines (for example, block and stratified bootstraps). To document several such extensions, we turn to an alternative example below, modeled after a simple IV regression example based on system data, as described in the help file of Stata’s ivregress. Here we extend to a case with multiple outcomes and examine both a one- and a two-sided test.
We begin with a (default) two-sided test, where we follow the implementation of the two-stage least-squares estimate from the
ivregress help file.
16 We use the same specification, where along with the outcome variable
rent, we also consider three other variables:
popden,
popgrow and
hsng. We do not make any claim to causality or consistency of the resulting estimates. These are simply shown as an illustration of the
rwolf command with an IV regression. In each case, the independent variable of interest is
hsngval, and this is instrumented with the variables indicated in the
iv() option. We include
pcturban as an additional control. We use 10,000 bootstrap replications (bootstrapping on observational units) and request a graph of the null distributions used in testing be reported (as discussed below).
The setup and output of this Romano–Wolf correction is displayed below. In this example, the p-values from the original IV models are quite low, suggesting evidence against the null that each coefficient on the variable hsngval is 0. The Romano–Wolf correction displayed in the final column results in inflated p-values (as designed), though the adjusted p-values are still relatively low.

Below, we document the same procedure but here conducting one-sided hypothesis tests. In each case, the null hypothesis in these tests will be of the form H 0 : β 1 ≤ 0, versus the alternative H 1 : β 1 > 0, where β 1 is the coefficient on hsngval in the second stage of the IV regression. For the sake of illustration, we multiply the two outcomes by −1, such that the sign on estimated in each IV regression is greater than 0. Along with the syntax described previously, the implementation of one-sided tests requires the use of the option onesided(). If onesided(negative) is specified, the null will be H 0 : β 1 ≤ 0; that is, negative values will provide more support for the null. On the other hand, if onesided(positive) is specified, the null will be H 0 : β 1 ≥ 0 in each case, such that positive values will provide more support for the null.

In each example, we specified the graph option to request as output the null distributions used to calculate the p-value in each case. Examining these distributions allows us to empirically observe how much more demanding the Romano–Wolf correction is compared with an uncorrected test.
In
figure 2 panel (a), we display these distributions in the two-sided case. Here the histogram presents the absolute value of each (Studentized) estimate from the bootstrap replications where the null is imposed, and the black dotted line presents an exact half-normal distribution. The actual Studentized value of the regression coefficient is displayed as a solid vertical line. In the top left panel, the first null distribution is considerably more demanding than the theoretical distribution, given that it accumulates the maximum coefficient estimated across each outcome. These null distributions become increasingly less demanding in the top right and bottom left panels because previously tested variables are removed from the pool to form the null distributions. Finally, in the bottom right corner (for the least significant variable), the null distribution is based on bootstrap replications from only this variable, and as such, the null distribution closely approximates the theoretical half-normal distribution.
In
figure 2 panel (b), we present the same null distributions but now based on the one-sided tests. Here the histogram documents the maximum values across the multiple variables in each bootstrap replication, and the black dotted line presents the theoretical normal distribution. Once again, when we consider outcomes for which more significant relationships are observed, the empirical distribution used to calculate the corrected
p-value is considerably more demanding than the black dotted distribution, which would be used under no correction and a normality assumption. In the case of the least significant variable (
popden), these two distributions are similar given that the null distribution is based only on Studentized regression estimates of the single regression where this is the outcome variable.
4.2 A nonstandard Studentized example
Each previous example has been based on the simple rwolf command syntax where a single independent variable is regressed on multiple outcome variables. This is frequently sufficient for a large number of implementations, such as cases where a single experimental treatment is assigned, and various outcomes are measured. In this case, the rwolf command can be implemented in one line and takes care of everything, including the full process of bootstrap draws, estimation of regression coefficients and standard errors, as well as the generation of null distributions and p-values. However, Romano–Wolf p-values can also be calculated for more complex setups, if the user wishes to pass the command the already-bootstrapped (or permuted) statistics and standard errors that have been calculated from the underlying models of interest. We document this flexibility in what remains of this section, using a bootstrap approach where our statistics of interest are a series of correlations.
We use an example and data documented in
Westfall and Young (1993), which was also previously used to demonstrate the effectiveness of the Romano–Wolf procedure in
Romano and Wolf (2005a). Although we refer to this as a nonstandard example, it is only nonstandard in the way it interacts with the syntax of
rwolf, given that the multiple tests are based on several independent variables and as such do not allow for a single independent variable to be indicated using the
indepvar() option.
This example considers pairwise correlations between state-average standardized Scholastic Aptitude Test (SAT) scores and several other state-level measures for the 48 mainland U.S. states plus Hawaii. These data—consisting simply of state-level measures of several variables of interest—are provided in table 6.4 of
Westfall and Young (1993, 197) as well as in the replication materials for this article. The variables considered are
satdev (the residuals from a regression of state-level SAT scores on the square root of the percent of students taking the exam in a given state), the student/teacher ratio in the state, the teacher salary, the percent of the population that is black, and the crime rate of each state.
In this case, the statistics of interest refer to simple correlations between pairs of variables of interest, and
p-values will be corrected for the fact that we are testing 10 hypotheses. To construct null distributions following (4) and (5), the
rwolf command requires an estimate of the original parameter of interest in each case (the pairwise correlation) along with a standard error. These values are used to construct
ts (as defined in section 2.2) for each of the
s multiple hypotheses and to order the hypotheses in terms of their relative significance. The command additionally requires the results from
M bootstrap replicates, where a resampled estimate of each statistic and its standard error is provided. We document such a case below, where in each of the multiple hypotheses the parameter of interest is the correlation between variables
ρ (which can be simply calculated using
corr in Stata) and its standard error, which, assuming normality, is calculated as (
Bowley 1928;
Zar 2010)
17To generate the various components that
rwolf uses to implement the multiplehypothesis correction, we first open the data and define in locals
var1 and
var2 the corresponding pairs to be tested. The idea in these locals is that we wish to calculate the correlation between the first variable listed in
var1 and the first variable listed in
var2, the correlation between the second variable listed in
var1 and the second variable listed in
var2, and so forth, through the correlation between the last variable listed in
var1 and the last variable listed in
var2. We calculate these correlations one by one in the
foreach loop in the code below. We loop over elements of the local
var1, and we take corresponding elements one by one from local
var2 using Stata’s
tokenize command.
18 These correlations and standard errors from the original data are then saved, respectively, as locals
c’i’ and
s’i’ to be later passed to the
rwolf command. Finally, we generate two series of 10 empty variables,
rho1–
rho10 and
std1–
std10, which will later be populated by resample-based correlation estimates and their standard errors.

A bootstrap procedure is then implemented based on 5,000 resamples. We initially expand the dataset to have 5,000 observations to store each of the bootstrap estimates; however, prior to calculating the correlations and standard errors in each replicate, we work only with the 49 state-level observations with SAT data. Each replicate is implemented in the main forvalues loop below. Within each of these 5,000 iterations, we first issue a preserve command to later restore the data toward the end of each iteration; this way, the bootstrap resample (bsample) begins with the original data in each iteration. Within each loop, lines 7–12 calculate the bootstrap correlations and corresponding standard errors, which are then filled in line by line in the variables rho1–rho10 and std1–std10 at the end of each loop.

Once we have stored the original estimates plus their standard errors and have variables containing resampled estimates along with their resampled standard errors, we can simply request the multiple-hypothesis correction from rwolf, as laid out in section 3. This is implemented below.
We pass to rwolf the varlist consisting of resampled estimates. The stdests( varlist ) option consists of bootstrap standard errors. Finally, the original correlations and standard errors from the (original) data are passed as numlists in pointestimates() and stderrs(). The graph option requests that a graph be produced documenting the null distributions used in each test, and noplusone requests that the p-value be calculated following (7) rather than the standard (6).
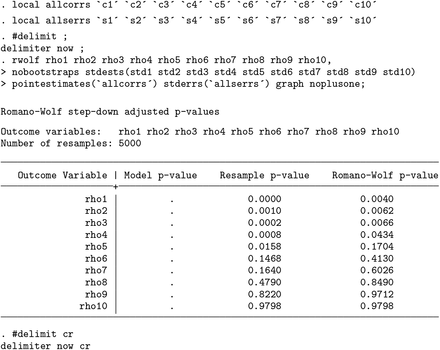
In this nonstandard implementation, no
Model p-value is returned because
rwolf itself does not estimate the original correlations, simply working with the estimates provided from the above code. In this case, we observe the
Resample p-value (which is not corrected for multiple-hypothesis testing), which is the results of comparing each original estimate with the null distribution, and the
Romano-Wolf p-value, where the multiple-hypothesis correction has been implemented as indicated in section 2.2. These results are similar to those observed in
Romano and Wolf (2005a, table 4) and would result in rejecting the same hypotheses if standard cutoffs (such as
α = 0.01,
α = 0.05, or
α = 0.10) were used.
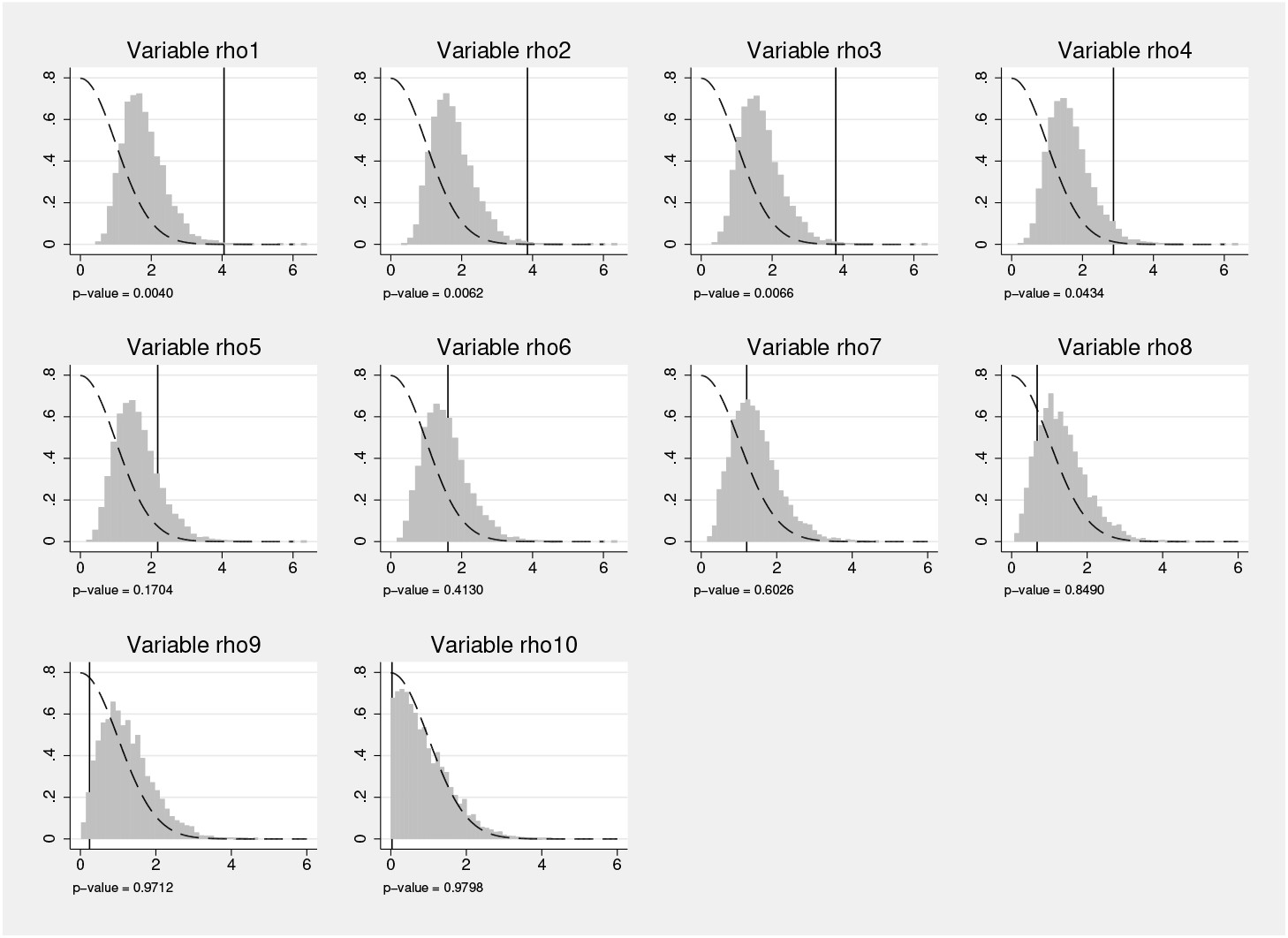
In
figure 3, we present the graph of null distributions, based on (5), for each hypothesis. As implied by the multiple-hypothesis testing algorithm, the null distributions become less demanding while moving from the most significant variable (top left-hand panel) to the least significant variable (left-hand panel in the final row).