

When automated fact-checking meets argumentation: Unveiling fake news through argumentative evidence
Abstract
1. Introduction
2. Related work
3. The LIARArg dataset
3.1. Data collection and filtering

3.2. Annotation scheme
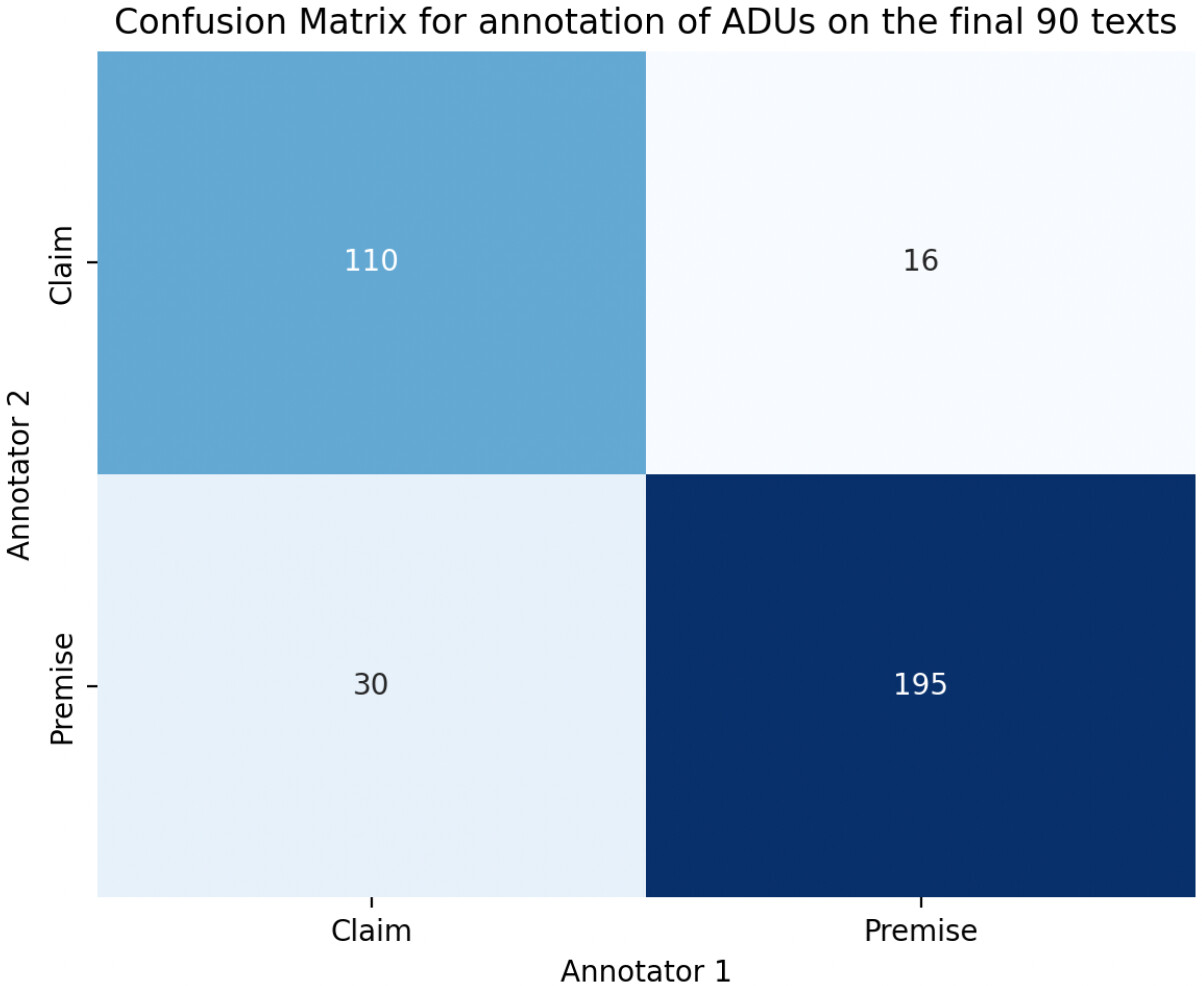
3.3. Annotation process
| Sample | Argument component | Argument Relation |
|---|---|---|
| 150 texts | 0.72 | 0.48 |
| 150 texts | 0.71 | 0.59 |
| 90 texts | 0.73 (substantial) | 0.61 (moderate) |

| Label | Items | Claims | Premises |
|---|---|---|---|
| True | 443 | 1.2 | 2.3 |
| Mostly-True | 529 | 1.4 | 2.5 |
| Half-True | 522 | 1.5 | 2.6 |
| Barely-True | 476 | 1.5 | 2.7 |
| False | 471 | 1.4 | 2.5 |
| Pants-on-fire | 391 | 1.4 | 2.4 |
| Total | 2,832 | 1.4 | 2.5 |
4. Experimental setting

4.1. General approach
4.2. Baselines
4.3. Proposed architectures
4.3.1. Multi-task learning (MTL)

4.3.2. Chain-of-thought (COT)
4.4. Fully automated FNC pipeline
4.5. Evaluation setup
5. Results
5.1. Results of MTL-based FNC
| Model | LG | KB | KGB | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Split | ST | +CC | +RC | +CCRC | ST | +CC | +RC | +CCRC | |
| Binary Valid | 0.58 | 0.64 | 0.63 | 0.69 | 0.66 | 0.67 | 0.67 | 0.73 | 0.72 |
| Binary Test | 0.60 | 0.65 | 0.64 | 0.70 | 0.66 | 0.68 | 0.68 | 0.74 | 0.72 |
| 6-Way Valid | 0.30 | 0.33 | 0.31 | 0.38 | 0.31 | 0.35 | 0.33 | 0.41 | 0.39 |
| 6-Way Test | 0.31 | 0.34 | 0.31 | 0.39 | 0.32 | 0.36 | 0.32 | 0.42 | 0.38 |
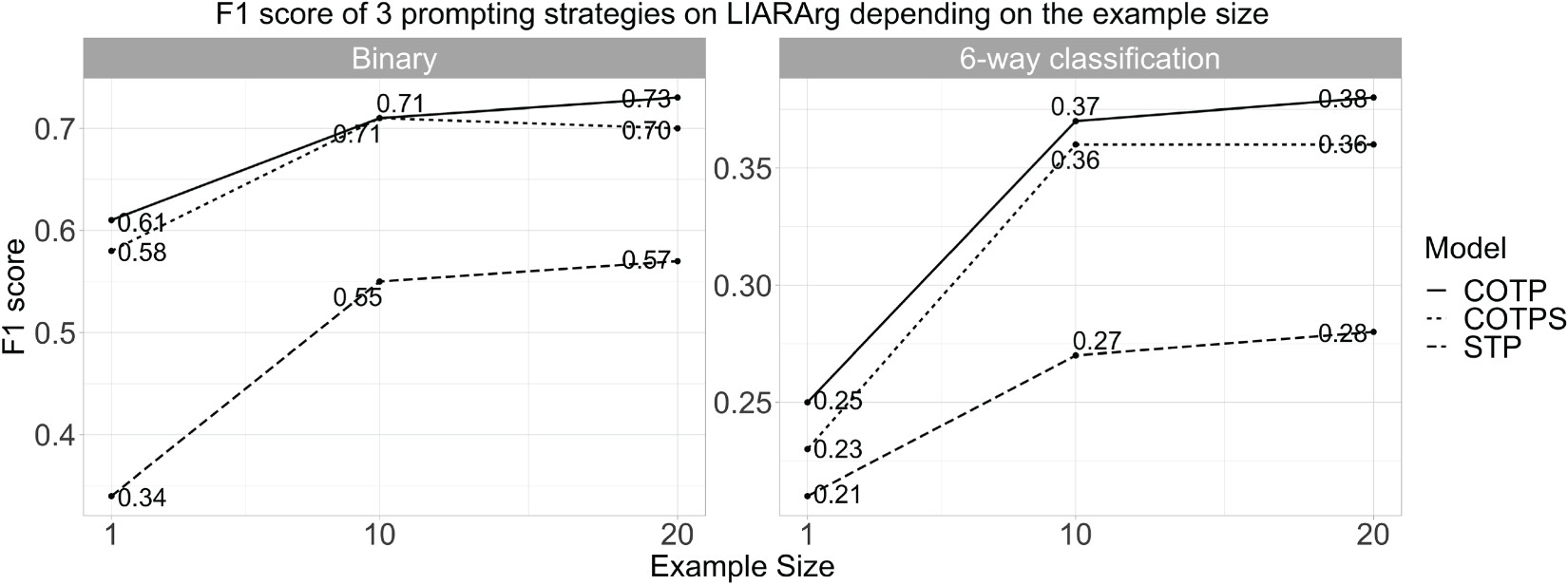
5.2. Results of COT-based FNC
| Model | KGB+RC | STP20 | COTP20 | COTPS20 |
|---|---|---|---|---|
| Binary Valid | 0.73 | 0.58 | 0.72 | 0.68 |
| Binary Test | 0.74 | 0.57 | 0.73 | 0.70 |
| 6-Way valid | 0.41 | 0.27 | 0.39 | 0.35 |
| 6-Way test | 0.42 | 0.28 | 0.38 | 0.36 |
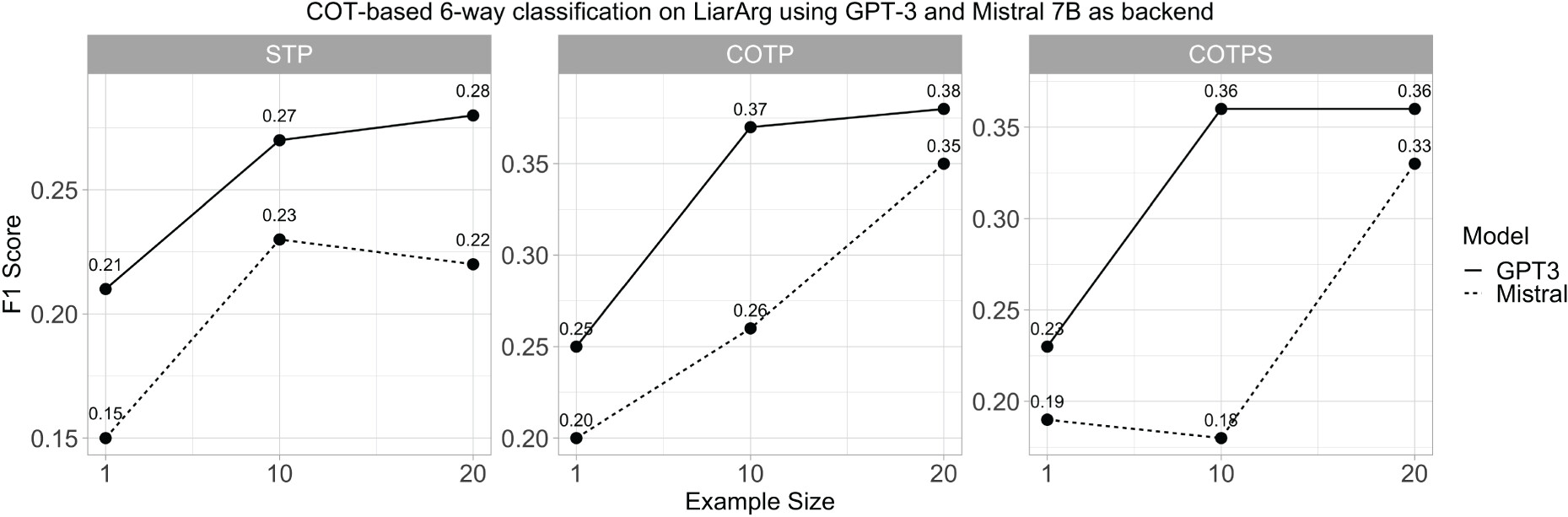
5.3. Ablation study on argument relations
| Model | Binary Valid | Binary Test | 6-Way valid | 6-Way test |
|---|---|---|---|---|
| KGB+RC | 0.73 | 0.74 | 0.41 | 0.42 |
| KGB+RC-F | 0.67 | 0.68 | 0.29 | 0.33 |
| COTP1 | 0.61 | 0.61 | 0.26 | 0.25 |
| COTP1-F | 0.57 | 0.58 | 0.23 | 0.23 |
| COTP20 | 0.72 | 0.73 | 0.39 | 0.38 |
| COTP20-F | 0.61 | 0.60 | 0.25 | 0.23 |
| COTPS1 | 0.59 | 0.58 | 0.24 | 0.23 |
| COTPS1-F | 0.53 | 0.54 | 0.20 | 0.21 |
| COTPS20 | 0.68 | 0.70 | 0.35 | 0.36 |
| COTPS20-F | 0.56 | 0.57 | 0.24 | 0.24 |
5.4. Results for the automated FNC pipeline
| Model | LG | KB | KGB | STP | COTP | COTPS | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Split | ST | +CC | +RC | +CCRC | ST | +CC | +RC | +CCRC | ||||
| Binary Valid | 0.65 | 0.71 | 0.70 | 0.76 | 0.72 | 0.73 | 0.73 | 0.77 | 0.72 | 0.62 | 0.73 | 0.70 |
| Binary Test | 0.64 | 0.72 | 0.71 | 0.77 | 0.72 | 0.74 | 0.71 | 0.78 | 0.72 | 0.61 | 0.74 | 0.69 |
| 6-Way Valid | 0.33 | 0.39 | 0.41 | 0.43 | 0.40 | 0.41 | 0.39 | 0.45 | 0.40 | 0.28 | 0.40 | 0.36 |
| 6-Way Test | 0.32 | 0.40 | 0.40 | 0.43 | 0.39 | 0.43 | 0.40 | 0.44 | 0.37 | 0.29 | 0.40 | 0.37 |
| Model | SOTA | KB | KGB | STP | COTP | COTPS | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Split | ST | +CC | +RC | +CCRC | ST | +CC | +RC | +CCRC | ||||
| 4-Way Test | 0.90 | 0.82 | 0.81 | 0.85 | 0.85 | 0.84 | 0.83 | 0.89 | 0.89 | 0.78 | 0.86 | 0.83 |
| Model | SOTA | KB | KGB | STP | COTP | COTPS | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Split | ST | +CC | +RC | +CCRC | ST | +CC | +RC | +CCRC | ||||
| Binary Test | 0.72 | 0.61 | 0.60 | 0.67 | 0.64 | 0.63 | 0.62 | 0.69 | 0.69 | 0.52 | 0.66 | 0.62 |
5.5. Error analysis
| Class | LG | KGB | KGB+RC |
|---|---|---|---|
| Pants-On-Fire | 0.35 | 0.50 | 0.60 |
| False | 0.29 | 0.32 | 0.39 |
| Mostly-false | 0.27 | 0.29 | 0.40 |
| Half-true | 0.26 | 0.25 | 0.35 |
| Mostly-true | 0.31 | 0.33 | 0.33 |
| True | 0.40 | 0.38 | 0.45 |
| Avg | 0.31 | 0.36 | 0.42 |
6. Concluding remarks
Conflicting interests
Funding
ORCID iD
References
Cite
Cite
Cite
Download to reference manager
If you have citation software installed, you can download citation data to the citation manager of your choice
Information, rights and permissions
Information
Published In

Keywords
Rights and permissions
Article versions
Authors
Metrics and citations
Metrics
Publication usage*
Total views and downloads: 1332
*Publication usage tracking started in December 2016
Publications citing this one
Receive email alerts when this publication is cited
Web of Science: 1 view articles Opens in new tab
Crossref: 1
- AMELIA: A family of multi-task end-to-end language models for argumentation
Figures and tables
Figures & Media
Tables
View Options
View options
PDF/EPUB
View PDF/EPUBAccess options
If you have access to journal content via a personal subscription, university, library, employer or society, select from the options below:
I am signed in as:
View my profileSign out

I can access personal subscriptions, purchases, paired institutional access and free tools such as favourite journals, email alerts and saved searches.
loading institutional access options
Alternatively, view purchase options below:
Access journal content via a DeepDyve subscription or find out more about this option.
