Introduction
Orofacial clefts (OFCs) are among the most common birth differences in the United States, affecting about 1 of every 600 live births.
1 Velopharyngeal insufficiency is a common observation in patients with OFCs such as cleft palate.
2 This insufficient closure of the velopharyngeal port leaks air up through the nose while talking, resulting in an abnormal amount of nasal resonance during speech, termed hypernasality. Patients with cleft palate receive primary palate repair surgery early on to restore musculature to its anatomic position and maximize potential for development of “normal” speech.
3 However, depending on the severity of the cleft, surgical technique, and timing of the primary palatoplasty, there are published literature that report up to 20% to 40% of primary cleft repair patients may require secondary palate revision surgery later in their life to improve speech.
4Routine perceptual speech assessments by professional speech language pathologists (SLP) are crucial for patients with cleft palate to monitor post operative speech outcomes.
5 SLPs help identify patients for early intervention when their speech worsens; however, there is a shortage of SLPs across the nation, especially in public schools and underserved areas.
6 This is even more magnified internationally, where shortage of SLPs is prevalent.
7 The high cost and limited access to SLPs in certain areas pose a barrier to care, and tools that can help screen speech issues could benefit children in under-served areas.
Automated screening tools powered by artificial intelligence (AI) offer a potential solution to this barrier, allowing for remote and low-cost methods of speech screening that can be widely accessible to patients with cleft lip and/or palate from all backgrounds. AI-aided tools can help screen for patients who may benefit from gold standard SLP speech evaluations, but reside in areas that lack qualified speech clinicians or where routine speech assessments are inaccessible. While AI cannot replace professional speech clinicians, it can be a valuable resource for SLPs to broaden their care to those in remote and underserved areas by being able to screen a larger number of patients.
Artificial intelligence (AI) is the science devoted to making machines “think” like humans, while machine learning (ML) is a type of AI that focuses on enabling computers to perform tasks independently and improve with experience. Deep learning (DL) is a subset of ML algorithms based on the artificial neural network that mimics the human brain. DL can be considered as the most recent and advanced type of machine learning algorithms.
8 In general, the distinction between deep learning and non-deep learning algorithms relates to how each algorithm processes input. Deep learning algorithms use multiple layers of processes to detect patterns, mimicking the human brain. Non-deep learning algorithms, on the other hand, are more linear and mainly compare input data to sample data.
9Traditionally, automated hypernasality detection tools have utilized non-deep learning algorithms, which combine feature engineering and vector-based classifiers, such as Support Vector Machines (SVM), Gaussian Mixture Models (GMM), and K-Nearest Neighbor (KNN).
10-13 Feature engineering and extraction are performed on the articulation process of hypernasality and are characteristic components of non-deep learning algorithms. These features are extracted based on the source-filter model of speech production
14 and have been heavily researched prior to the introduction of more advanced deep learning AI algorithms. The source-filter theory describes speech production as a 2-stage process, the generation of a sound source and the filtering of that sound by the vocal tract.
14 The severity of hypernasality is related to the size of the gap in velopharyngeal insufficiency and directly affects speech articulation, thus earlier research focused heavily on feature engineering and extraction based on this model of speech production.
11 Based on this model, a wide spectrum of acoustic features was engineered for this preprocessing step, looking for ways to isolate the most predictive acoustic features of hypernasal speech. These features can be summarized into 4 main categories: glottal-excitation-based features, vocal-tract-characteristic-based features, nasal-formant-based features, and other acoustic features based on the whole source-filter model.
15Glottal-excitation-based features focus on capturing information related to the glottal excitation signal, which is generated by the periodic vibration of the vocal folds during voiced sounds.
11 In individuals with cleft palate and hypernasality, impaired velopharyngeal movement and incomplete velopharyngeal closure can occur during glottal articulation. However, this phenomenon is specific and typically observed during glottal stop substitutions, where a consonant is replaced by a sound produced in the back of the throat known as a glottal stop.
16 Such substitutions often serve as a compensatory mechanism for velopharyngeal insufficiency (VPI). Pitch, on the other hand, refers to the vibratory characteristics of the vocal folds which can also become distorted in patients with VPI.
11 Features derived from pitch include Jitter, which measures the variation of the cycle-to-cycle pitch period; shimmer, which refers to the pitch period amplitude; pitch perturbation quotient (PPQ) which quantifies the variability of the pitch period evaluated in 5 consecutive cycles; and amplitude perturbation quotient (APQ) which calculates the average difference between the amplitude of 5 preceding and successive pitch periods.
11,17,18 Vocal-tract-characteristic-based features leverage the shape and dimensions of the vocal tract to examine the articulatory process within the source-filter model of speech production. The vocal tract extends from the glottis to the lips and undergoes shape changes during articulation and pronunciation.
19 Spectral and cepstral characteristics capture these functions and movements, reflecting the alterations in vocal tract shape.
15 Basic speech spectral characteristics are typically computed using short-time Fourier transform (STFT), while LP-based cepstrum isolates the vocal tract information by removing the glottal excitation source.
20 Mel frequency cepstral coefficients (MFCCs) and one-third octave spectra combine vocal tract information with human auditory characteristics using a logarithmic function.
21 Nasal-formant-based features involve modeling the vocal tract and are crucial cues for hypernasal speech detection. While oral formants resulting from resonance in the oral cavity, such as the first oral formant (F1) and second oral formant (F2), are well-established, research has shown the existence of nasal formants in hypernasal speech as well.
22 Examples of nasal-formant-based features include the maximum cross-correlation value between the input and the resynthesized speech signal,
23 features based on the Teager energy operator (TEO),
24 the vowel space area (VSA),
25 and acoustic measures based on the group delay function.
26 Acoustic features based on the source-filter model encompass a comprehensive consideration of the articulation and pronunciation processes for hypernasality detection. While the 2 parts source and filter are interdependent, the theory states that the characteristics of the vocal tract significantly affect the performance of the source.
14 In patients with velopharyngeal insufficiency, air escapes from the nose, and decreases the intraoral pressure. These patients exert more pressure on their larynx to compensate for the velopharyngeal insufficiency and to decrease hypernasality. Consequently, this would cause vocal problems and lead to changes in the vocal tract that will affect the performance of the source.
27 These features include the harmonic-to-noise ratio (HNR),
28 normalized error prediction,
29 normalized noise energy,
28 wavelet coefficients,
26 energy ratio of oral, and nasal speech,
26 bionic wavelet transform entropy,
30 and nonlinear dynamics features.
31 Once these distinctive features of hypernasal speech are isolated from the speech samples, the extracted features are utilized to detect hypernasality using correlational analysis, threshold settings, or vector-based classifiers such as non-deep learning algorithms which include SVM and GMM (See
Appendix 1). In correlation studies, the extracted features and calculated parameters are compared with reference values to detect hypernasality. In threshold studies, a threshold is set to detect hypernasality. Lastly, in vector-based models, a combination of extract features is combined with shallow and deep classifiers to detect hypernasality.
15 While these feature dependent algorithms are effective at processing bits of speech that have been preprocessed, they are not effective at processing entire unfiltered speech samples independently due to the presence of noise between segments of interest. Preprocessing helps reduce entire speech samples into fragments of nasal and oral vowels and consonants containing the high yield features described above, which can then be easily processed without distractor inputs, greatly increasing the algorithm’s detection accuracy. This preprocessing step remains mainly a manual process but can be done automatically with an Automatic Speech Recognition system such as the 1 described by Maier et al.
12 On the other hand, most recent papers published on automatic hypernasality detection have trended toward using deep learning algorithms which do not require a preprocessing feature extraction step and can be trained using entire speech recordings.
10 Examples of these AI algorithms include Deep Neural Networks (DNN), Convoluted Neural Networks (CNN), and Long-Short Term Models (LSTM).
15,32,33 This review will focus on the categorization, unique features, and clinical utility of these non-DL and DL algorithms.
Previous systematic reviews
34,35 focused on providing a broad overview of all clinical applications of artificial intelligence and machine learning in cleft care, including genetic risk assessment, speech assessment, surgery aid, and others. This systematic review studies AI algorithms that distinctly focus on evaluation of hypernasality in patients with cleft palate. We identify the 3 main categories of current state-of-the-art hypernasality detection algorithms, discuss their advantages and disadvantages, and propose future directions for research which will promote the integration of these systems into clinical practice.
Methods
Research Design
This review was conducted following the Preferred Reporting Items for Systematic review and Aeta-analysis (PRISMA) guidelines and the 2020 checklist.
36Inclusion and Exclusion Criteria
This systematic review focuses on the applications of artificial intelligence techniques used in automatic speech analysis for patients with cleft lip and/or palate (CL/P). Inclusion criteria required that studies: (1) describe machine learning algorithms for automatic detection of cleft speech, (2) report quantitative data describing accuracy of the tool’s algorithm against some gold standard metric such as ratings provided by speech language pathologists, (3) focus on software that was trained using real person speech samples. Studies describing algorithms that detect hypernasality in both pediatric and adult populations were included. Only published journal articles were considered for review. All publication years were considered
Exclusion criteria were as follows: (1) reviews, technique articles, book chapters, conference proceedings, and papers, incomplete articles (eg, only abstracts available), (2) articles not available in English, (3) studies in which AI algorithms was not directly involved in the analysis of a patient’s speech, (4) articles that did not focus on speech analysis of patients with cleft lip and/or palate (eg, surgical techniques).
Systematic Database Search
Systematic search was conducted on June 28, 2021, with a medical school reference librarian in 8 databases (PubMed, Scopus, ACM digital library, Linguistics, and language behavior abstracts, Institute of Electrical, and Electronics Engineers, CINAHL, PsychInfo, Cochrane). Medical Subject Heading terms include ones describing cleft speech “Velopharyngeal Insufficiency,” “Hypernasal,” “Cleft lip,” and “Cleft palate,” and terms describing AI/ML algorithms “Machine Learning,” “Neural Networks,” “Artificial Intelligence,” and “Machine Language.” Wildcard asterisk was applied to all search terms and the Boolean operator “OR” was used between similar terms such as ones describing cleft speech or AI/ML algorithms, while the Boolean operator “AND” was used to link the 2 sets of terms, ones describing cleft speech, and ones describing AI/ML algorithms. The full syntax of the search was the following: (“Artificial Intelligence”[MeSH Terms] OR “artificial intelligence”[tw] OR “Machine Learning”[MeSH Terms] OR “machine language”[tw] OR “machine learning”[tw] OR “neural network”[tw] OR “neural networks”[tw] AND (“Cleft Lip”[Mesh] OR “cleft lip”[tw] OR “Cleft Palate”[Mesh] OR “cleft palate”[tw] OR “cleft speech”[tw] OR “Velopharyngeal Insufficiency”[mesh] OR “velopharyngeal insufficiency”[tw] OR hypernasal*[tw]). Note that studies describing machine learning algorithms trained in foreign languages were also included because the goals of the studies were similar and focused on detecting a common feature of velopharyngeal insufficiency, hypernasality.
Search results from all databases were combined and duplicates were removed. Title and abstract screenings were conducted by 2 reviewers independently for concordance of article relevance. Cohen’s Kappa was calculated for inter-rater reliability analysis yielding k = 0.919 and k = 1, respectively. The full-text review of post-screening studies was done for eligibility, and disagreements were discussed to reach consensus.
Data Collection
Three categories of data were collected from the included articles: (1) the type of machine learning algorithm used, (2) speech sample database variables, and (3) whether feature extraction was required prior to training of the AI algorithms. Type of ML algorithm refers to the AI algorithm’s structure (eg, deep learning or support vector machine) utilized to train the hypernasality detection algorithm. Speech sample database variables included the size of the database (eg, number of speech samples), the language used, and demographic data, such as age ranges (eg, pediatric vs adult), and sex distribution. Feature extraction, described in the introduction of this paper, describes a pre-processing procedure that computer scientists use to extract the most useful phonetic features from a speech recording to feed the AI algorithm to achieve the highest accuracy in detection of hypernasality. Traditionally, feature extraction is a characteristic component of non-deep learning algorithms, while more advanced deep learning algorithms typically do not require this preprocessing step in its development, though some deep learning algorithms still utilize feature extraction. For a non-deep learning algorithm to detect hypernasality, distinct phonetic features need to be extracted from whole speech recordings using the many models of speech production, such as Mel Frequency Cepstral Coefficients (MFCCs), Glottal Activity Detection (GADs), Shimmer, and Jitter just to name a few. On the other hand, deep learning algorithms did not require a preprocessing feature extraction step and can be trained using entire speech recordings.
10 Lastly, quantitative data on each algorithm’s concordance were collected. The concordance score is the main method of analyzing the success of an algorithm at detecting hypernasality and defined as the agreement between algorithmic detection and perceptual detection of hypernasality by speech clinicians, reported as a numerical value between 0 and 1.0.
Results
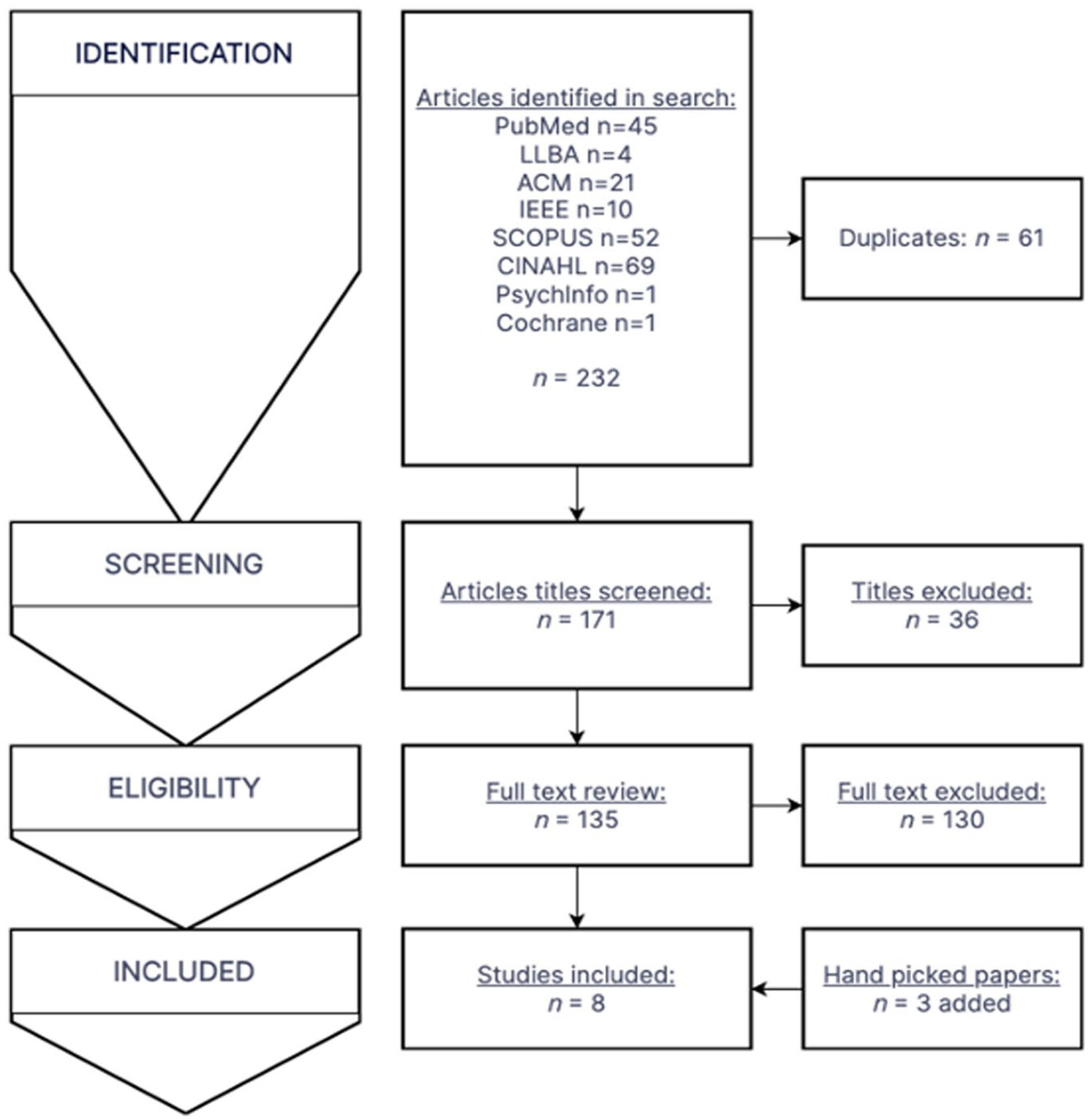
The multiple database search was completed on June 28, 2021, with results combined and duplicates removed. The search yielded 171 unique articles, and a title and abstract screen eliminated 36 articles based on inclusion and exclusion criteria, which yielded 135 articles (Cohen’s kappa
k = 0.919). A full text review of the 135 articles yielded 5 which met all inclusion criteria (Cohen’s kappa
k = 1). From the review of citations, 3 handpicked papers were additionally included, which were all from databases not searched in the initial search. In total, 8 articles met all criteria and were eligible for inclusion in the systematic review. The attrition flowchart detailing the study section is shown in
Figure 1.
All papers described the process of training and testing an algorithm with labeled cleft speech samples by speech clinicians except for 1 study, which described training an algorithm with healthy speech corpus and then testing it with a labeled cleft speech database.
37 While most papers focused on 1 algorithm,
11,15,32,33,37 some papers explored multiple approaches to maximize the concordance of a specific type of machine learning algorithm.
10,12,13 In the case of papers with multiple combinations of approaches and algorithms, the combination that achieved the highest concordance was selected as the main algorithm to be included in this review.
These 8 papers described 10 distinct machine learning algorithms developed for automatic hypernasality detection, which are listed in
Table 1.
10-13,15,32,33,37 While each algorithm utilized different methods and approaches, they can be characterized in the following 2 ways: (1) Feature dependent versus Feature independent algorithms, and (2) Deep learning versus non-deep learning algorithms. The 2 classification systems are described below.
The source-filter theory describes speech production as a 2-stage process, the generation of a sound source and the filtering of that sound by the vocal tract.
14 The severity of hypernasality is related to the size of the gap in velopharyngeal insufficiency and directly affects speech articulation, thus earlier research focused on feature engineering and extraction based on this model of speech production.
11 Based on this model, a wide spectrum of acoustic features was engineered for this preprocessing step, looking for ways to isolate the most predictive acoustic features of hypernasal speech. Once these distinctive features of hypernasal speech were isolated from the speech samples, they were then fed to a machine learning algorithm to be used as input data. These feature dependent algorithms consisted of non-deep learning algorithms, such as: SVM, GMM, HMM, which were not effective at processing entire unfiltered speech samples independently due to the presence of noise between segments of interest. Thus, a preprocessing step helped reduce entire speech samples into fragments which can then be easily processed without distractor inputs. This preprocessing step is mainly a manual process but can be done automatically with an Automatic Speech Recognition system as described by Maier et al
12On the other hand, feature independent ML algorithms do not require a preprocessing step and have only been achieved with deep learning algorithms. Entire speech samples can be fed directly to the algorithm, creating an end-to-end system that greatly reduces the amount of human intervention needed. This feature-independent category was achieved via the application of deep learning algorithms with its multiple layers of processes that can independently extract the most predictive features. These end-to-end systems have appeared within the last 4 years, using more advanced types of machine learning algorithms such as: Deep Neural Networks, Convoluted Neural Networks, and Long Short-Term Memory.
10While the development and approaches of these hypernasality detection algorithms vary greatly, they can be categorized into 3 main groups using the 2-classification system described above. All 10 algorithms can be classified based on the type of machine learning algorithm used (non-deep learning or deep learning) and whether they are feature dependent or independent:
(1) Feature dependent, non-deep learning algorithms
(2) Feature dependent, deep learning algorithms
(3) Feature independent, deep learning algorithms.
These algorithms are listed and described in
Table 1.
Feature Dependent Non-deep Learning Algorithms
The majority of algorithms fell in this category (n = 5).
10-13,33 This category represents the traditional approach of pairing feature extraction techniques with non-deep learning algorithms (
Table 1). The concordance of these automatic hypernasality detection algorithms (AHDA) against professional speech clinician assessment ranged from 0.81 to 0.92, with an average concordance of 0.85, the lowest of the 3 groups. The average number of cleft speech database sizes used to train each algorithm was 3587. The types of machine learning algorithms utilized include Support Vector Machine, K-Nearest Neighbor, Hidden Markov Model, and Gaussian Mixture Modeling.
Feature Dependent Deep Learning Algorithms
Two algorithms fell in this category (n = 2).
32,33 This category represents the non-traditional approach of combining traditional feature engineering with more advanced deep learning algorithms. One of the studies
32 showed that LSTM-DRNN had more robust feature extraction ability and better classification ability compared to non-deep learning algorithms combined with the preprocessing step. The concordance of these AHDAs were extremely similar, ranging from 0.9334 to 0.9335, the highest of the 3 groups, even though the algorithms were trained across 2 completely different patient populations in India and China respectively (
Table 1). The average number of cleft speech database sizes used to train each algorithm was 3921. The types of ML algorithms used include Deep Neural Network and LSTM-DRNN respectively.
Feature Independent Deep Learning Algorithms
Three algorithms fell in this category (n = 3).
15,37 This category represents the most advanced approach to AHDAs using feature independent deep learning algorithms. The systems are end-to-end meaning there is no feature extraction involved and entire sentences can be fed in the algorithm without preprocessing. The concordance of these AHDAs range from 0.797 to 0.975, with an average of 0.91, the middle of the 3 groups. The average number of cleft speech database sizes used to train each algorithm was 6306 (
Table 1). Due to the lack of a comparable quantifying speech sample metric in one of the studies,
37 the size of its training database was not factored into the average database size. The types of ML algorithms used include Deep Neural Networks and Convoluted Neural Networks.
One of the 3 algorithms
33 should be noted to have trained their algorithm using healthy speech corpus and not hypernasal speech, which has never been done previously. All other studies described in this review utilized speech from cleft palate patients. While their concordance was lower in the healthy speech corpus group (0.797), the flexibility of deep neural networks to be able to learn from healthy speech should not be overlooked, especially given that the main bottleneck in AHDA development is the shortage of quality cleft speech samples. Due to the lack of a comparable quantifying speech sample metric, its 100 h of healthy speech corpus was not factored into the average number of cleft speech database size for the last group of algorithms.
Speech Database Size versus Concordance
Another observation from the results presented in
Table 1 is the correlation between the number of speech samples used to train the algorithms and the concordance of the algorithms to professional speech clinician ratings. The trendline in
Figure 2 is relatively flat and the
R2 value is low (.396) indicating a weak relationship. While a positive relationship between the 2 measures exists (number of speech samples available and the level of concordance achieved) the relationship is not strong. Additionally, the number of speech samples varied greatly, ranging from 300 to 10 080. However, despite the large differences between the number of cleft speech sample sizes, the difference between concordances were not nearly as large, ranging from 0.81 to 0.98. It should be noted that in
Figure 2 one algorithm
33 was excluded due its use of non-cleft speech corpus and lack of a comparable quantifying speech sample metric, which was present in all other algorithms. Thus, the assumption that training with a larger amount of data will always lead to better models is not correct, other factors such as the quality of the input data is equally as important and applies to both non-deep learning and deep learning algorithms.
8Discussion
This systematic review studies the use of artificial intelligence to detect hypernasality, which is a clinically relevant outcome of speech surgeries such as cleft palate repair. Overall, all 3 groups yielded high levels of accuracy in the detection of hypernasality, but deep learning algorithms were able to consistently achieve higher concordances, regardless of feature extraction usage. The highest average concordance (0.93) was achieved by the feature dependent deep learning algorithms, which combines traditional approaches of feature extraction with the latest deep learning algorithms. Second (0.91), was the feature independent deep learning algorithms which are the most advanced end-to-end automatic hypernasality speech detection systems requiring minimal human intervention. Third (0.85), was achieved by the feature dependent non-deep learning algorithms, which follows a more traditional approach to creating ML algorithms. As described previously, the main differences between the 3 groups of algorithms are whether it uses feature extraction and whether it uses traditional machine learning algorithms or more advanced deep learning algorithms. While algorithmic design differences greatly affect the concordances achieved by these algorithms, one should also consider the importance of the amount of training data available to each research team and thus their algorithms.
This study has 3 main findings. First, this is a new and burgeoning area of research, as there are only 8 studies on artificial intelligence for assessment of hypernasal speech, all published within the past 8 years except for 1 paper which was published much earlier in 2009.
12 Second, detection of hypernasality by artificial intelligence algorithms is highly concordant with expert opinion, encouraging automatic hypernasality detection algorithm (AHDA) as a reliable method of screening for hypernasality. Third, the approach and methodology in these studies varied greatly, while still maintaining a high level of accuracy, suggesting that researchers can customize their algorithms to best fit their needs and resources.
Novel Technology
In the literature, artificial intelligence has been established as an appropriate screening methodology for a number of health-related outcomes such as breast cancer, glaucoma, and cardiovascular health to just name a few.
38-40 Despite the advantages of artificial intelligence and machine learning, the use of AI and ML to assess hypernasality is relatively new. Of the 8 studies discussed in this review, 5 papers were published within the past 3 years and all but1 study was published within the past 6 years. The results from these studies are promising and invite further research into this new frontier of hypernasal speech assessment.
Highly Concordant
All studies found that ML algorithms were able to detect hypernasal speech with high concordance compared to professional speech clinician ratings. Furthermore, this remained true despite a variety of factors which differed from study to study such as different native languages, types of ML algorithms used, and patient populations tested (pediatric and adult). These findings support the adaptability of ML algorithms and enhance the feasibility of using ML as a screening tool in future clinical practice. These initial findings are promising and suggest that ML algorithms have unharnessed potential for large-scale, low-cost, and objective speech assessment screening for cleft palate patients.
High Quality Results in the Setting of Limited Resources
Having more data is almost always better in training machine learning algorithms; more data translates to more features, more dimensions, and measures to explore, and more detailed results. Thus, building a quality cleft speech database is critical in the advancement of AHDA research, but remains one of its main obstacles. The quantity of cleft speech data may also be a practical concern for institutions wanting to build their own AHDA to provide low-cost and rapid screenings. Since both non-deep learning and deep learning algorithms can achieve similar levels of concordance, an institution with a limited cleft speech database may utilize non-deep learning algorithms for their accuracy requiring fewer speech samples, while an institution with a large cleft speech database may prefer deep learning algorithms which can achieve higher accuracies but require large amounts of data.
Limitations
Our systematic review is limited by the available studies. A number of the studies were published by the same author, which may have unintended publication bias from researchers who have previously been successful in designing and executing experiments. Some authors also trained their algorithms using the same cleft speech corpus; it is possible that some speech samples may have been used in multiple studies. This may have reduced the variability of speech samples analyzed by each algorithm. Sex is a significant factor which can influence speech acoustics but was only reported by 1 paper out of the 8.
15 Not knowing the distribution or whether a cleft speech database used to train an algorithm is biased toward male or female speech limits its generalizability. Additionally, these ML algorithms were developed in different countries and trained with different native languages, including English (United States), Kannada (India), Mandarin (China), Persian (Iran), Columbian (Columbia), Spanish (Spain, Chile, Ecuador), German (Germany), and Peruvian (Peru). While the mechanical production of hypernasality due to velopharyngeal insufficiency remains constant across different languages, innate characteristics of each language may have unintentional effects on the ability of ML algorithms to detect hypernasality. For example, an algorithm trained with Mandarin may not function as accurately when used on English speech samples. This phenomenon has not been studied in literature and thus reduces the utility of direct comparison between concordances achieved by these algorithms.
Finally, as with any study, this study is limited to the population and techniques studied and may or may not be generalizable to automated analyses of hypernasality in all languages. However, the languages addressed in this paper are already quite diverse, and the concordances of the ML algorithms show a similar degree of accuracy. Therefore, we believe that ML algorithms may be applicable to detect hypernasality in a much wider range of languages and populations.
Future Directions
Continued assessment of speech on a routine basis is a crucial component of postoperative care for children with cleft palate. This provides a useful post-surgical application where ML algorithms can help address health care gaps and obstacles in cleft speech care. The goal of regular post-surgical speech screenings is to monitor and screen for worsening hypernasal speech, which can affect up to 20% to 40% of primary cleft palate repair patients.
4 However, some children are not able to see SLPs regularly, especially if the limited visits are due to financial or geographic barriers (eg, patients who live in rural areas or in places where SLPs are not readily accessible). This approach both complements the trend toward telemedicine and home-based interventions in speech-language pathology
41-43 and provides a potential solution to the mismatch in provision of speech services that disproportionately affects vulnerable populations.
44 Speech intelligibility involves both the listener and speaker.
45 ML algorithms can eliminate the listener bias of close contacts, including family and teachers, who may have adapted to better understand the child’s speech, without relying on the expert ears of SLPs who may not be available to all communities. The rapid results and high accessibility make ML algorithms an appropriate tool for SLPs to measure progress and serve to augment and complement their specialized speech services. Automated hypernasality detection systems cannot and should not replace professional speech therapy, but it has the potential to extend the reach of SLPs into underserved areas and remove health care barriers experienced by cleft speech patients.
Overall, this review of current literature suggests that ML is an appropriate platform for the assessment of hypernasality, with the potential to expand into new speech frontiers, such as postoperative remote monitoring of cleft palate surgery. Methods to improve reliability and adoption into clinical practice include training ML algorithms with diverse patient populations, including different languages, and testing in clinical settings and using speech samples beyond its training database. Future avenues of research can explore the inclusion of cleft and non-cleft speech samples in a training database, since 1 study demonstrated the ability to train ML algorithms on non-cleft speech. This can increase the size of the training sample size and overcome the limitations of collecting cleft speech samples.