1 Enhanced audiovisual training
Given the growing popularity of audiovisual materials, both researchers and practitioners have shown increasing interest in how learners acquire vocabulary while viewing video clips containing target lexical items (for an overview, see
Perez, 2022). Over the past decade, extensive empirical evidence has demonstrated that while mere exposure to videos can lead to incidental learning (
Peters & Webb, 2018), learning outcomes improve substantially when pedagogical enhancements are introduced to help learners attend to target items during viewing – an approach termed ‘enhanced audiovisual training’.
One widely used enhancement involves captions. A large body of research has shown that learning gains are greater when videos are accompanied by captions (e.g.
Peters, 2019;
Teng, 2025;
Winke et al., 2010; see
Kurokawa et al., 2024;
Perez et al., 2013, for meta-analyses). Kurokawa et al.’s (2024) meta-analysis revealed that captioned viewing led to an average relative gain of 19.70%, compared to 15.15% for uncaptioned viewing – a roughly 5% advantage. According to the subtitle principle (
Mayer et al., 2020), this benefit arises because captions act as a redundant channel that aids word segmentation, recognition, and retention. This is particularly advantageous for L2 learners, who often struggle to parse continuous speech due to unclear word boundaries and rapid speech rates. By providing concurrent orthographic and auditory input, captions facilitate the mapping of phonological forms to orthographic representations and semantic meanings. This dual-modality input supports both bottom-up decoding and top-down comprehension, enhancing learners’ ability to notice and integrate new lexical items (
Vanderplank, 2016).
Empirical studies (e.g.
Perez, 2020;
Teng, 2025) consistently report that captioned videos yield greater gains in meaning recognition and recall than uncaptioned videos, especially among beginner- and intermediate-level learners. Captioned input also tends to outperform other modalities such as listening-only, reading, or uncaptioned viewing, a finding attributed to dual-channel encoding and the ability of captions to direct learners’ attention to key lexical targets. Moreover, captions can reduce comprehension difficulties and maintain engagement, particularly when learners encounter unfamiliar topics or accents (
Perez, 2022).
Another enhancement involves explicit vocabulary guidance prior to viewing. Many earlier studies emphasizing incidental learning have deliberately avoided announcing vocabulary tests beforehand, aiming to ensure that participants focused solely on message comprehension (e.g.
Majuddin et al., 2021). However, for pedagogical purposes, other researchers have examined whether providing explicit vocabulary guidance before viewing can facilitate learning. Such guidance typically informs learners that vocabulary tests will follow, encouraging greater attention to lexical items during viewing (i.e. the notion of combined intentional and incidental learning; Laufer & Hulstijin, 2001). For example,
Peters et al. (2009) found that announcing vocabulary tests significantly increased learning gains from reading activities. In the audiovisual domain,
Majuddin et al. (2026) likewise demonstrated that explicit pre-viewing guidance substantially enhanced vocabulary learning from audiovisual training, even after a single exposure, whereas minimal gains were observed when the same training was delivered without such guidance (cf.
Majuddin et al., 2021).
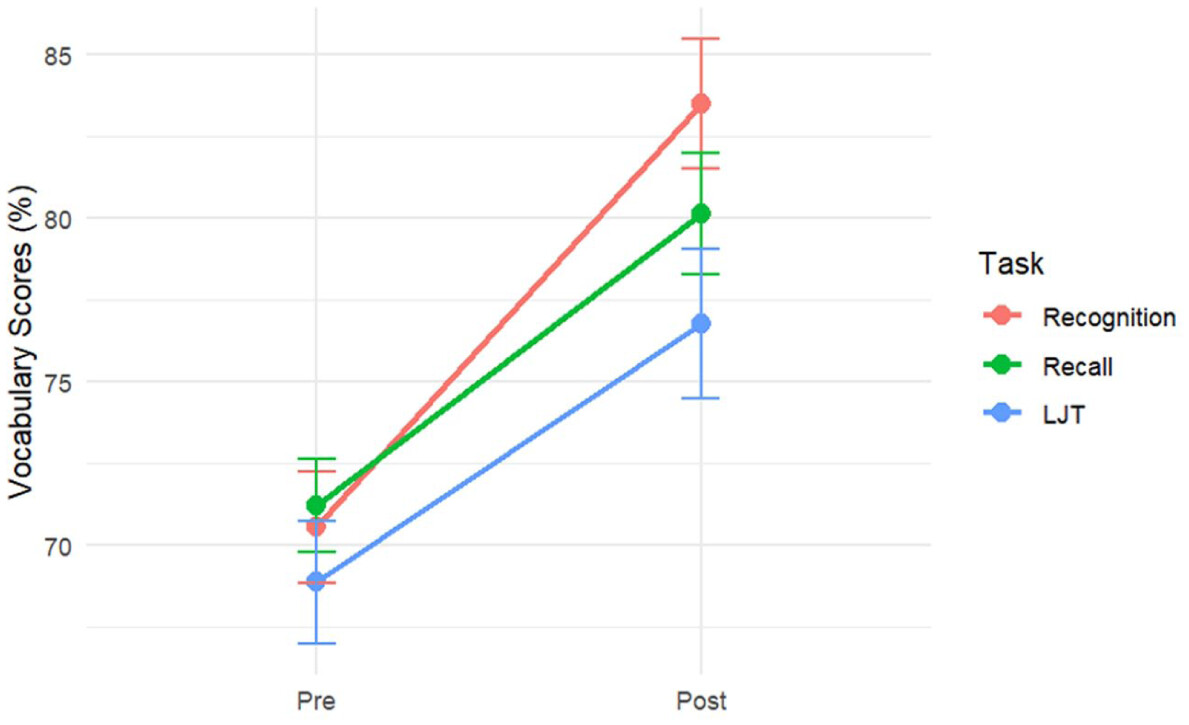
Building on these findings, the present study adopted this well-established enhanced/explicit audiovisual training method to investigate how learning gains emerge across two dimensions of word knowledge: declarative and automatized. Specifically, we tested the hypothesis that enhanced audiovisual training would lead to clear gains in declarative knowledge but more limited improvements in automatized knowledge.
2 Skill acquisition framework of L2 phonological vocabulary
Many scholars have highlighted that developing robust phonological vocabulary knowledge (including the knowledge of single-word items and multiword expressions) is a cornerstone of L2 speech proficiency. Indeed, extensive research has identified such knowledge as a primary contributor to the attainment of global listening (e.g.
Cheng et al., 2023;
Wallace, 2022) and speaking skills (e.g.
De Jong et al., 2012;
Tavakoli & Uchihara, 2020).
Nation’s (2013) influential framework suggests that phonological vocabulary knowledge can be characterized by two core aspects: form–meaning mapping and use-in-context. The former refers to the ability to associate the phonological form of a word with its meaning, while the latter entails deploying this knowledge in semantically, collocationally, and grammatically appropriate ways within broader linguistic contexts. Form–meaning mapping typically involves recognizing individual target words (or phrases) in isolation, whereas use-in-context reflects the capacity to understand and integrate those words (or phrases) within larger clause- or sentence-level units. In this sense, L2 listening proficiency is generally assumed to progress from basic form–meaning mapping toward more advanced use-in-context skills.
In
Schmitt’s (2019) methodological synthesis of L2 vocabulary research, it was noted that the vast majority of studies have concentrated almost exclusively on form–meaning mapping – typically assessed through meaning recognition and recall tasks (for methodological foundations and distinctions between recognition and recall, see
González-Fernández & Schmitt, 2020). However, Schmitt underscored that surprisingly few have directly examined the use-in-context dimension, despite its arguably greater ecological validity in capturing the lexical demands of real-world listening and speaking.
To advance theoretical and methodological understanding in this area, recent studies (
Saito et al., 2025;
Uchihara et al., 2025) have reconceptualized the two-stage development of phonological vocabulary knowledge – i.e. from form–meaning mapping to use-in-context – within the framework of L2 phonological vocabulary development. Traditionally applied to rule-based morphosyntactic learning in instructed contexts, skill acquisition theory distinguishes between declarative, procedural, and automatized knowledge (
DeKeyser & Suzuki, 2025). According to this model, second language learning progresses sequentially from declarative knowledge (‘knowing what’), to procedural knowledge (‘knowing how’ in controlled settings), and ultimately to automatized knowledge (‘knowing how’ in real-life and global contexts). Drawing on conceptual parallels between
Nation’s (2013) framework and skill acquisition theory,
Saito et al. (2025) and
Uchihara et al. (2025) aligned form–meaning mapping with declarative/procedural knowledge and use-in-context with automatized knowledge.
Under this view, form–meaning mapping involves the explicit association between a word’s sound and meaning, typically assessed through recognition and recall tasks. At this stage, learners build declarative representations of lexical items through explicit, form-focused instruction, reflecting changes in symbolic representations of knowledge. By contrast, use-in-context corresponds to automatized knowledge, defined as the ability to access and integrate lexical items quickly, accurately, and consistently within broader sentential contexts. After developing declarative and procedural knowledge, repeated exposure to authentic L2 aural input (e.g. TV shows, films, conversations with native and non-native speakers) enables learners to integrate lexical items into surrounding discourse as cohesive units at the sentence level. This, in turn, leads to faster, more accurate, and more stable processing with reduced attentional demands (
Ellis, 2006), reflecting qualitative improvements in subsymbolic representations of knowledge.
In his more recent work, DeKeyser has revised and expanded skill acquisition theory to encompass a wider range of instructed L2 learning domains, with the aim of offering a more nuanced account of L2 development in classroom settings and clearer pedagogical implications (
DeKeyser & Suzuki, 2025). Building on this,
Suzuki and DeKeyser (in press) have explicitly applied the framework to the development of phonological vocabulary knowledge in the context of real-life listening and speaking. Echoing
Saito et al. (2025) and
Uchihara et al. (2025),
Suzuki and DeKeyser (in press) argue that:
initial declarative knowledge, such as that called upon in form–meaning recognition and recall, must be automatized through repeated contextual use to become truly employable . . . Achieving automaticity enables accurate and efficient lexical processing needed to support fluent comprehension and production. This is not just about knowing what a word means, but being able to access and integrate that meaning effortlessly during real-time language use.
According to skill acquisition theory in instructed L2 learning (
DeKeyser & Suzuki, 2025;
Suzuki & DeKeyser, in press), a key distinction lies between the non-automatized (i.e. declarative and procedural) and automatized dimensions of knowledge. On the one hand, declarative knowledge is generally assessed through single-modal measures that allow learners to focus their attention on specific knowledge components under relatively controlled conditions. Within the domain of phonological vocabulary, this dimension has typically been operationalized through meaning recognition tasks (
McLean et al., 2015) or meaning recall tasks (
Cheng et al., 2023), both of which require learners to explicitly retrieve form–meaning associations.
On the other hand, automatized knowledge is examined using dual-modal tasks that test learners’ ability to access target linguistic representations while simultaneously engaging in meaningful communication. Such tasks emulate real-life communicative contexts, where accurate and rapid use of language must occur largely subconsciously while multiple linguistic subsystems are activated in parallel. These conditions reveal the extent to which learners can deploy knowledge automatically in the service of fluent communication. Despite its theoretical and pedagogical importance, however, relatively little empirical work has addressed how best to capture the automatized dimension of phonological vocabulary knowledge (
Suzuki & Elgort, 2023).
In applied linguistics, automatized L2 knowledge – defined as the accurate, prompt, and stable application of acquired linguistic information – is commonly evaluated through acceptability judgement tasks (
Suzuki & Elgort, 2023, for a comprehensive overview). For example, automatized morphosyntactic knowledge is often assessed with grammaticality judgement tasks (GJTs;
Plonsky et al., 2020), where L2 learners evaluate the grammatical correctness of aurally or visually presented sentences. Such tasks include both well-formed and error-containing sentences, thereby probing learners’ morphosyntactic knowledge at the sentence level rather than in isolation.
Although relatively few studies have adopted acceptability judgement tasks to assess vocabulary, some pioneering work has done so.
Ellis et al. (2008) investigated how first language (L1) and second language (L2) speakers judged the grammaticality of word sequences, contrasting well-formed expressions (e.g.
by the way) with ill-formed ones (e.g.
by way the). Their findings showed that L1 speakers’ judgements were primarily driven by collocational strength, whereas L2 speakers relied more on word frequency. Similarly,
Foster et al. (2014) asked advanced L2 learners to detect non-nativelike collocations embedded in narrative passages (e.g. ‘he replied
by a shrug’ instead of ‘he replied
with a shrug’). Their results indicated that learners with higher proficiency and an earlier age of arrival were more accurate in identifying non-standard combinations. Notably, both studies presented stimuli in written form.
More recently, researchers have developed and validated the lexicosemantic judgement task (LJT) as a measure of the automatized dimension of L2 phonological vocabulary knowledge (
Saito et al., 2025;
Uchihara et al., 2025). In an LJT, learners evaluate whether a target word is used appropriately in a given sentence – for example, a correct usage (e.g.
I work hard for promotion) versus an incorrect one (e.g.
I ate a promotion last night). Drawing on dual-task paradigms, the LJT captures the complexities of lexical processing during holistic listening comprehension, requiring learners to integrate lexical, phonological, morphosyntactic, and pragmatic cues in real time. Unlike traditional recognition-based tests that isolate specific lexical items, the LJT engages multiple linguistic subsystems simultaneously, thereby better reflecting the automaticity required for fluent comprehension.
Validation studies with Japanese learners of English have provided empirical support for the LJT. Administering the LJT alongside recognition and recall tasks as well as the standardized TOEIC listening test, these studies found that recognition and recall measures clustered together, while the LJT loaded onto a distinct factor. This pattern suggests that recognition and recall primarily index declarative knowledge, whereas the LJT more effectively taps automatized knowledge. Furthermore, LJT performance showed stronger correlations with TOEIC listening scores (r = .60–.70) compared with recognition and recall measures (r = .40–.50), underscoring the LJT’s closer alignment with real-time global comprehension skills.